Qui est en STAGE et s'ennuie actuellement?
Le 06 juin 2019 à 10:08:39 Matt_spyro38 a écrit :
Le 06 juin 2019 à 10:07:21 silverfox31 a écrit :
Le 06 juin 2019 à 10:04:53 silverfox31 a écrit :
Le 06 juin 2019 à 09:56:28 Matt_spyro38 a écrit :
Whiisky-003Tu serais pas de Grenoble des fois ?

P'tain y en a qui s'y connaissent en python ?
J'ai un data frame (librairie pandas) avec des variables sous le format date heure (2015-01-01 00:00:00). Appelons le data frame "test"
Et parfois il y a des doublons (en gras) de dates genre :
2015-01-01 00:00:00
2015-01-01 00:01:00
2015-01-01 00:02:00
2015-01-01 00:03:00
2015-01-01 00:03:00
2015-01-01 00:04:00
2015-01-01 00:05:00
2015-01-01 00:06:00
2015-01-01 00:03:00
2015-01-01 00:03:00
2015-01-01 00:06:00Et le soucis c'est que parfois ces doublons reviennent un peu plus tard dans le data frame
(cf les deux avant dernières lignes
)
Ce que j'aimerais c'est créer une variable permettant de repérer les doublons (appelons la g par exemple) du genre :
2015-01-01 00:00:00 0
2015-01-01 00:01:00 0
2015-01-01 00:02:00 0
2015-01-01 00:03:00 0
2015-01-01 00:03:00 1
2015-01-01 00:04:00 0
2015-01-01 00:05:00 0
2015-01-01 00:06:00 0
2015-01-01 00:03:00 0
2015-01-01 00:03:00 1
2015-01-01 00:06:00 0J'ai donc créé une copie du data frame test et je l'ai appelé test3 (y avait déjà un test2
test3['g']=test.groupby('Date_Local_Time').cumcount()
Sauf que ce PUTAIN DE CODE va me modifier l'ordre des lignes et les mettre dans l'ordre des heures, hors je veux que les lignes restent dans l'ordre original.
2015-01-01 00:00:00 0
2015-01-01 00:01:00 0
2015-01-01 00:02:00 0
2015-01-01 00:03:00 0
2015-01-01 00:03:00 1
2015-01-01 00:03:00 2
2015-01-01 00:03:00 3
2015-01-01 00:04:00 0
2015-01-01 00:05:00 0
2015-01-01 00:06:00 0
2015-01-01 00:06:00 0
Bon j'post au cas où y ait des jean-codage dans le coin, ce serait top si vous aviez une solution...
Tu peux créer un tableaux dans lequel tu stocke toutes les chaines traités et tu vérifie à chaque tour si la chaîne à traiter est dedans ou non. Si elle est déjà dans le tableau tu la traite pas.
C'est stocké dans quoi tes donnés ? Un dictionnaire, une liste, un tuple... ?
Date_Local_Time est une variable d'un data frame (tableau de données) (librairie pandas
)
Whisky

sinon ta la fonction set 
Salut les quilles
Plus que deux heures de taf ici et demain weekend  La journée passe plutôt vite, pas de deadline mais j'ai 2-3 projets sur lesquels je dois bosser, même si ça me laisse quand même un peu de temps pour glander quand ma collègue est pas derrière moi
La journée passe plutôt vite, pas de deadline mais j'ai 2-3 projets sur lesquels je dois bosser, même si ça me laisse quand même un peu de temps pour glander quand ma collègue est pas derrière moi 
Le 06 juin 2019 à 10:11:17 silverfox31 a écrit :
Le 06 juin 2019 à 10:08:39 Matt_spyro38 a écrit :
Le 06 juin 2019 à 10:07:21 silverfox31 a écrit :
Le 06 juin 2019 à 10:04:53 silverfox31 a écrit :
Le 06 juin 2019 à 09:56:28 Matt_spyro38 a écrit :
Whiisky-003P'tain y en a qui s'y connaissent en python ?
J'ai un data frame (librairie pandas) avec des variables sous le format date heure (2015-01-01 00:00:00). Appelons le data frame "test"
Et parfois il y a des doublons (en gras) de dates genre :
2015-01-01 00:00:00
2015-01-01 00:01:00
2015-01-01 00:02:00
2015-01-01 00:03:00
2015-01-01 00:03:00
2015-01-01 00:04:00
2015-01-01 00:05:00
2015-01-01 00:06:00
2015-01-01 00:03:00
2015-01-01 00:03:00
2015-01-01 00:06:00Et le soucis c'est que parfois ces doublons reviennent un peu plus tard dans le data frame
Ce que j'aimerais c'est créer une variable permettant de repérer les doublons (appelons la g par exemple) du genre :
2015-01-01 00:00:00 0
2015-01-01 00:01:00 0
2015-01-01 00:02:00 0
2015-01-01 00:03:00 0
2015-01-01 00:03:00 1
2015-01-01 00:04:00 0
2015-01-01 00:05:00 0
2015-01-01 00:06:00 0
2015-01-01 00:03:00 0
2015-01-01 00:03:00 1
2015-01-01 00:06:00 0J'ai donc créé une copie du data frame test et je l'ai appelé test3 (y avait déjà un test2
test3['g']=test.groupby('Date_Local_Time').cumcount()
Sauf que ce PUTAIN DE CODE va me modifier l'ordre des lignes et les mettre dans l'ordre des heures, hors je veux que les lignes restent dans l'ordre original.
2015-01-01 00:00:00 0
2015-01-01 00:01:00 0
2015-01-01 00:02:00 0
2015-01-01 00:03:00 0
2015-01-01 00:03:00 1
2015-01-01 00:03:00 2
2015-01-01 00:03:00 3
2015-01-01 00:04:00 0
2015-01-01 00:05:00 0
2015-01-01 00:06:00 0
2015-01-01 00:06:00 0
Bon j'post au cas où y ait des jean-codage dans le coin, ce serait top si vous aviez une solution...
Tu peux créer un tableaux dans lequel tu stocke toutes les chaines traités et tu vérifie à chaque tour si la chaîne à traiter est dedans ou non. Si elle est déjà dans le tableau tu la traite pas.
C'est stocké dans quoi tes donnés ? Un dictionnaire, une liste, un tuple... ?
Date_Local_Time est une variable d'un data frame (tableau de données) (librairie pandas
Whisky
sinon ta la fonction set
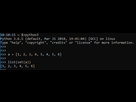
Je ne veux pas supprimer les doublons en fait, je veux les garder. Je veux juste mettre un "compteur" qui augmente de 1 dès qu'il voit deux valeurs à la suite.
J'ai d'ailleurs réussi à le faire, mais le soucis c'est que mon code change l'ordre des lignes (je ne sais pas si je me suis très bien expliqué... ).
Ce que je veux (je te laisse regarder les lignes en gras pour que tu vois le souci) :
(T'as la variable Date_Local_Time, et la variable g qui compte le nombre de valeurs identiques à la suite)
Date_Local_Time g
2015-01-01 00:00:00 0
2015-01-01 00:01:00 0
2015-01-01 00:02:00 0
2015-01-01 00:03:00 0
2015-01-01 00:03:00 1
2015-01-01 00:04:00 0
2015-01-01 00:05:00 0
2015-01-01 00:06:00 0
2015-01-01 00:03:00 0
2015-01-01 00:03:00 1
2015-01-01 00:07:00 0
Ce que j'ai :
Date_Local_Time g
2015-01-01 00:00:00 0
2015-01-01 00:01:00 0
2015-01-01 00:02:00 0
2015-01-01 00:03:00 0
2015-01-01 00:03:00 1
2015-01-01 00:03:00 2
2015-01-01 00:03:00 3
2015-01-01 00:04:00 0
2015-01-01 00:05:00 0
2015-01-01 00:06:00 0
2015-01-01 00:07:00 0
Mon code met tous les "minuit 3" ensemble, alors que je veux qu'ils restent dans l'ordre original (même si ça parait wtf)...

Le 06 juin 2019 à 09:17:02 MrOkkin- a écrit :
Salut les kheys, je vais de ce pas rattraper tout les messages que j'ai rater mais d'abord petit bonjour + rapport
Ce soir les amis, c'est le grand soir, c'est le matchVous aurez évidemment un compte rendu dès ce soir normalement
Sinon ce matin à peine arriver qu'on m'a dit de venir au café avec eux (ce que je n'ai fait qu'une fois) bon pas si horrible la discussion et puis ça m'a permis de ne pas bosser direct en arrivant

Aller hop je vais rattraper tout les messages maintenant



On compte sur vous pour la jouer physique ce soir et ne pas vous retenir sur les tacles 
Le 06 juin 2019 à 09:23:02 JoanesEzponda a écrit :
Bonne question pour lundi, dans le doute je vais pas y aller.La solidarité, c'est non
Pour les stagiaires c'est férié ! SAUF si c'est expressément ECRIT dans la convention que le stagiaire doit travailler ce jour là 
Le 06 juin 2019 à 10:02:53 silverfox31 a écrit :
Tous les matin on a une réunion à 9H30 entre les équipe pour que tout le monde dit ce qu'il a fait et à faire
Sauf que moi je suis réglé comme une horloge et 9H30 c'est l'heure de mon caca
Du coup tous les matin c'est une torture pendant 15-30 min



Les réunions à 9h30 quel enfer .gif ":)")
Moi j'ai les écossais qui foutent réunion de 12h30 à 13h vendredi comme ça pour eux c'est juste avant manger, et chez nous bah
Le 06 juin 2019 à 10:15:03 Lingsho a écrit :
Salut les quillesPlus que deux heures de taf ici et demain weekend
Le khey qui se met bien 
Le 06 juin 2019 à 10:17:51 Matt_spyro38 a écrit :
Le 06 juin 2019 à 10:11:17 silverfox31 a écrit :
Le 06 juin 2019 à 10:08:39 Matt_spyro38 a écrit :
Le 06 juin 2019 à 10:07:21 silverfox31 a écrit :
Le 06 juin 2019 à 10:04:53 silverfox31 a écrit :
Le 06 juin 2019 à 09:56:28 Matt_spyro38 a écrit :
Whiisky-003P'tain y en a qui s'y connaissent en python ?
J'ai un data frame (librairie pandas) avec des variables sous le format date heure (2015-01-01 00:00:00). Appelons le data frame "test"
Et parfois il y a des doublons (en gras) de dates genre :
2015-01-01 00:00:00
2015-01-01 00:01:00
2015-01-01 00:02:00
2015-01-01 00:03:00
2015-01-01 00:03:00
2015-01-01 00:04:00
2015-01-01 00:05:00
2015-01-01 00:06:00
2015-01-01 00:03:00
2015-01-01 00:03:00
2015-01-01 00:06:00Et le soucis c'est que parfois ces doublons reviennent un peu plus tard dans le data frame
Ce que j'aimerais c'est créer une variable permettant de repérer les doublons (appelons la g par exemple) du genre :
2015-01-01 00:00:00 0
2015-01-01 00:01:00 0
2015-01-01 00:02:00 0
2015-01-01 00:03:00 0
2015-01-01 00:03:00 1
2015-01-01 00:04:00 0
2015-01-01 00:05:00 0
2015-01-01 00:06:00 0
2015-01-01 00:03:00 0
2015-01-01 00:03:00 1
2015-01-01 00:06:00 0J'ai donc créé une copie du data frame test et je l'ai appelé test3 (y avait déjà un test2
test3['g']=test.groupby('Date_Local_Time').cumcount()
Sauf que ce PUTAIN DE CODE va me modifier l'ordre des lignes et les mettre dans l'ordre des heures, hors je veux que les lignes restent dans l'ordre original.
2015-01-01 00:00:00 0
2015-01-01 00:01:00 0
2015-01-01 00:02:00 0
2015-01-01 00:03:00 0
2015-01-01 00:03:00 1
2015-01-01 00:03:00 2
2015-01-01 00:03:00 3
2015-01-01 00:04:00 0
2015-01-01 00:05:00 0
2015-01-01 00:06:00 0
2015-01-01 00:06:00 0
Bon j'post au cas où y ait des jean-codage dans le coin, ce serait top si vous aviez une solution...
Tu peux créer un tableaux dans lequel tu stocke toutes les chaines traités et tu vérifie à chaque tour si la chaîne à traiter est dedans ou non. Si elle est déjà dans le tableau tu la traite pas.
C'est stocké dans quoi tes donnés ? Un dictionnaire, une liste, un tuple... ?
Date_Local_Time est une variable d'un data frame (tableau de données) (librairie pandas
Whisky
sinon ta la fonction set
Je ne veux pas supprimer les doublons en fait, je veux les garder. Je veux juste mettre un "compteur" qui augmente de 1 dès qu'il voit deux valeurs à la suite.
J'ai d'ailleurs réussi à le faire, mais le soucis c'est que mon code change l'ordre des lignes (je ne sais pas si je me suis très bien expliqué...
Ce que je veux (je te laisse regarder les lignes en gras pour que tu vois le souci) :
(T'as la variable Date_Local_Time, et la variable g qui compte le nombre de valeurs identiques à la suite)Date_Local_Time g
2015-01-01 00:00:00 0
2015-01-01 00:01:00 0
2015-01-01 00:02:00 0
2015-01-01 00:03:00 0
2015-01-01 00:03:00 1
2015-01-01 00:04:00 0
2015-01-01 00:05:00 0
2015-01-01 00:06:00 0
2015-01-01 00:03:00 0
2015-01-01 00:03:00 1
2015-01-01 00:07:00 0Ce que j'ai :
Date_Local_Time g
2015-01-01 00:00:00 0
2015-01-01 00:01:00 0
2015-01-01 00:02:00 0
2015-01-01 00:03:00 0
2015-01-01 00:03:00 1
2015-01-01 00:03:00 2
2015-01-01 00:03:00 3
2015-01-01 00:04:00 0
2015-01-01 00:05:00 0
2015-01-01 00:06:00 0
2015-01-01 00:07:00 0Mon code met tous les "minuit 3" ensemble, alors que je veux qu'ils restent dans l'ordre original (même si ça parait wtf)...
Je n'ai jamais utilisé panda. Met ta question sur stackoverflow, soit assez précis avec un bout de code pour que ce soit plus clair.
Tu me link ça après.
Le 06 juin 2019 à 10:26:04 zbeboverissou a écrit :
Le 06 juin 2019 à 09:17:02 MrOkkin- a écrit :
Salut les kheys, je vais de ce pas rattraper tout les messages que j'ai rater mais d'abord petit bonjour + rapport
Ce soir les amis, c'est le grand soir, c'est le matchSinon ce matin à peine arriver qu'on m'a dit de venir au café avec eux (ce que je n'ai fait qu'une fois) bon pas si horrible la discussion et puis ça m'a permis de ne pas bosser direct en arrivant
Aller hop je vais rattraper tout les messages maintenant
On compte sur vous pour la jouer physique ce soir et ne pas vous retenir sur les tacles

Malheureusement les talces sont interdits  Pas de bol
Pas de bol
Le 06 juin 2019 à 10:31:59 Free_benalla a écrit :
Whisky >tes en Master science des donnes à Montpellier ? Ta fais licence miashs à gre ?
Non pas du tout, j'étais à l'institut de Géographie Alpine à Grenoble, et là je fais un Master sur la Gestion des Littoraux et de la Mer
Le 06 juin 2019 à 10:34:04 T7O96F32 a écrit :
Bonjours les clés, je suis en stage a Mercedes, et actuellement, je M'ENNUIE
Stage de quoi ? dans une concession ?
Le 06 juin 2019 à 10:34:04 T7O96F32 a écrit :
Bonjours les clés, je suis en stage a Mercedes, et actuellement, je M'ENNUIE
En Allemagne ?
Le 06 juin 2019 à 10:27:10 silverfox31 a écrit :
Le 06 juin 2019 à 10:17:51 Matt_spyro38 a écrit :
Le 06 juin 2019 à 10:11:17 silverfox31 a écrit :
Le 06 juin 2019 à 10:08:39 Matt_spyro38 a écrit :
Le 06 juin 2019 à 10:07:21 silverfox31 a écrit :
Le 06 juin 2019 à 10:04:53 silverfox31 a écrit :
Le 06 juin 2019 à 09:56:28 Matt_spyro38 a écrit :
Whiisky-003P'tain y en a qui s'y connaissent en python ?
J'ai un data frame (librairie pandas) avec des variables sous le format date heure (2015-01-01 00:00:00). Appelons le data frame "test"
Et parfois il y a des doublons (en gras) de dates genre :
2015-01-01 00:00:00
2015-01-01 00:01:00
2015-01-01 00:02:00
2015-01-01 00:03:00
2015-01-01 00:03:00
2015-01-01 00:04:00
2015-01-01 00:05:00
2015-01-01 00:06:00
2015-01-01 00:03:00
2015-01-01 00:03:00
2015-01-01 00:06:00Et le soucis c'est que parfois ces doublons reviennent un peu plus tard dans le data frame
Ce que j'aimerais c'est créer une variable permettant de repérer les doublons (appelons la g par exemple) du genre :
2015-01-01 00:00:00 0
2015-01-01 00:01:00 0
2015-01-01 00:02:00 0
2015-01-01 00:03:00 0
2015-01-01 00:03:00 1
2015-01-01 00:04:00 0
2015-01-01 00:05:00 0
2015-01-01 00:06:00 0
2015-01-01 00:03:00 0
2015-01-01 00:03:00 1
2015-01-01 00:06:00 0J'ai donc créé une copie du data frame test et je l'ai appelé test3 (y avait déjà un test2
test3['g']=test.groupby('Date_Local_Time').cumcount()
Sauf que ce PUTAIN DE CODE va me modifier l'ordre des lignes et les mettre dans l'ordre des heures, hors je veux que les lignes restent dans l'ordre original.
2015-01-01 00:00:00 0
2015-01-01 00:01:00 0
2015-01-01 00:02:00 0
2015-01-01 00:03:00 0
2015-01-01 00:03:00 1
2015-01-01 00:03:00 2
2015-01-01 00:03:00 3
2015-01-01 00:04:00 0
2015-01-01 00:05:00 0
2015-01-01 00:06:00 0
2015-01-01 00:06:00 0
Bon j'post au cas où y ait des jean-codage dans le coin, ce serait top si vous aviez une solution...
Tu peux créer un tableaux dans lequel tu stocke toutes les chaines traités et tu vérifie à chaque tour si la chaîne à traiter est dedans ou non. Si elle est déjà dans le tableau tu la traite pas.
C'est stocké dans quoi tes donnés ? Un dictionnaire, une liste, un tuple... ?
Date_Local_Time est une variable d'un data frame (tableau de données) (librairie pandas
Whisky
sinon ta la fonction set
Je ne veux pas supprimer les doublons en fait, je veux les garder. Je veux juste mettre un "compteur" qui augmente de 1 dès qu'il voit deux valeurs à la suite.
J'ai d'ailleurs réussi à le faire, mais le soucis c'est que mon code change l'ordre des lignes (je ne sais pas si je me suis très bien expliqué...
Ce que je veux (je te laisse regarder les lignes en gras pour que tu vois le souci) :
(T'as la variable Date_Local_Time, et la variable g qui compte le nombre de valeurs identiques à la suite)Date_Local_Time g
2015-01-01 00:00:00 0
2015-01-01 00:01:00 0
2015-01-01 00:02:00 0
2015-01-01 00:03:00 0
2015-01-01 00:03:00 1
2015-01-01 00:04:00 0
2015-01-01 00:05:00 0
2015-01-01 00:06:00 0
2015-01-01 00:03:00 0
2015-01-01 00:03:00 1
2015-01-01 00:07:00 0Ce que j'ai :
Date_Local_Time g
2015-01-01 00:00:00 0
2015-01-01 00:01:00 0
2015-01-01 00:02:00 0
2015-01-01 00:03:00 0
2015-01-01 00:03:00 1
2015-01-01 00:03:00 2
2015-01-01 00:03:00 3
2015-01-01 00:04:00 0
2015-01-01 00:05:00 0
2015-01-01 00:06:00 0
2015-01-01 00:07:00 0Mon code met tous les "minuit 3" ensemble, alors que je veux qu'ils restent dans l'ordre original (même si ça parait wtf)...
Je n'ai jamais utilisé panda. Met ta question sur stackoverflow, soit assez précis avec un bout de code pour que ce soit plus clair.
Tu me link ça après.
J'vais encore essayer quelques trucs, et si jamais je ne trouve toujours pas j'irai (re)faire un tour sur stack ouais merci de ton aide
Le 06 juin 2019 à 10:31:00 MrOkkin- a écrit :
Le 06 juin 2019 à 10:26:04 zbeboverissou a écrit :
Le 06 juin 2019 à 09:17:02 MrOkkin- a écrit :
Salut les kheys, je vais de ce pas rattraper tout les messages que j'ai rater mais d'abord petit bonjour + rapport
Ce soir les amis, c'est le grand soir, c'est le matchSinon ce matin à peine arriver qu'on m'a dit de venir au café avec eux (ce que je n'ai fait qu'une fois) bon pas si horrible la discussion et puis ça m'a permis de ne pas bosser direct en arrivant
Aller hop je vais rattraper tout les messages maintenant
On compte sur vous pour la jouer physique ce soir et ne pas vous retenir sur les tacles
Malheureusement les talces sont interdits
Pas de bol
Un petit coup d'épaule prononcer lors d'un duel en bord de terrain 
Le 06 juin 2019 à 10:34:04 T7O96F32 a écrit :
Bonjours les clés, je suis en stage a Mercedes, et actuellement, je M'ENNUIE
Vas faire un tour en voiture
Le 06 juin 2019 à 10:35:31 T7O96F32 a écrit :
Encore 3 semaines et demi, ou je n'ai pas de mission de stage, trop hâte de faire mon rapport qui doit faire TRENTE pages environ
50 pages ici kheyou, je suis de tout coeur avec toi
Le 06 juin 2019 à 10:42:39 zbeboverissou a écrit :
Le 06 juin 2019 à 10:31:00 MrOkkin- a écrit :
Le 06 juin 2019 à 10:26:04 zbeboverissou a écrit :
Le 06 juin 2019 à 09:17:02 MrOkkin- a écrit :
Salut les kheys, je vais de ce pas rattraper tout les messages que j'ai rater mais d'abord petit bonjour + rapport
Ce soir les amis, c'est le grand soir, c'est le matchSinon ce matin à peine arriver qu'on m'a dit de venir au café avec eux (ce que je n'ai fait qu'une fois) bon pas si horrible la discussion et puis ça m'a permis de ne pas bosser direct en arrivant
Aller hop je vais rattraper tout les messages maintenant
On compte sur vous pour la jouer physique ce soir et ne pas vous retenir sur les tacles
Malheureusement les talces sont interdits
Un petit coup d'épaule prononcer lors d'un duel en bord de terrain

Ca serait un coup du hasard entrainé dans ma course je bouscule un peu  Sinon je viens de me rendre compte que la c'est les phases de poules donc 3 matchs, mais si on gagne on va plus loin et donc je vais devoir jouer d'autres jours
Sinon je viens de me rendre compte que la c'est les phases de poules donc 3 matchs, mais si on gagne on va plus loin et donc je vais devoir jouer d'autres jours
Cinquante ?? Ah quand même
Jvais tenter de Dodge le rapport en parlant surtout de l'entreprise plutôt que ce que je fais moi (attendre que le temps passe)
Le 06 juin 2019 à 10:45:00 MrOkkin- a écrit :
Le 06 juin 2019 à 10:42:39 zbeboverissou a écrit :
Le 06 juin 2019 à 10:31:00 MrOkkin- a écrit :
Le 06 juin 2019 à 10:26:04 zbeboverissou a écrit :
Le 06 juin 2019 à 09:17:02 MrOkkin- a écrit :
Salut les kheys, je vais de ce pas rattraper tout les messages que j'ai rater mais d'abord petit bonjour + rapport
Ce soir les amis, c'est le grand soir, c'est le matchSinon ce matin à peine arriver qu'on m'a dit de venir au café avec eux (ce que je n'ai fait qu'une fois) bon pas si horrible la discussion et puis ça m'a permis de ne pas bosser direct en arrivant
Aller hop je vais rattraper tout les messages maintenant
On compte sur vous pour la jouer physique ce soir et ne pas vous retenir sur les tacles
Malheureusement les talces sont interdits
Un petit coup d'épaule prononcer lors d'un duel en bord de terrain
Ca serait un coup du hasard entrainé dans ma course je bouscule un peu
Sinon je viens de me rendre compte que la c'est les phases de poules donc 3 matchs, mais si on gagne on va plus loin et donc je vais devoir jouer d'autres jours
L'année dernière avec la coupe du monde ça devait être qqch 
Le 06 juin 2019 à 10:46:56 zbeboverissou a écrit :
Le 06 juin 2019 à 10:45:00 MrOkkin- a écrit :
Le 06 juin 2019 à 10:42:39 zbeboverissou a écrit :
Le 06 juin 2019 à 10:31:00 MrOkkin- a écrit :
Le 06 juin 2019 à 10:26:04 zbeboverissou a écrit :
Le 06 juin 2019 à 09:17:02 MrOkkin- a écrit :
Salut les kheys, je vais de ce pas rattraper tout les messages que j'ai rater mais d'abord petit bonjour + rapport
Ce soir les amis, c'est le grand soir, c'est le matchSinon ce matin à peine arriver qu'on m'a dit de venir au café avec eux (ce que je n'ai fait qu'une fois) bon pas si horrible la discussion et puis ça m'a permis de ne pas bosser direct en arrivant
Aller hop je vais rattraper tout les messages maintenant
On compte sur vous pour la jouer physique ce soir et ne pas vous retenir sur les tacles
Malheureusement les talces sont interdits
Un petit coup d'épaule prononcer lors d'un duel en bord de terrain
Ca serait un coup du hasard entrainé dans ma course je bouscule un peu
L'année dernière avec la coupe du monde ça devait être qqch
C'est clair ils devaient être bouillants les quinqas
Données du topic
- Auteur
- unstalkable
- Date de création
- 2 avril 2019 à 10:07:20
- Nb. messages archivés
- 29549
- Nb. messages JVC
- 28476