J'AI PRIS CHATGPT PRO A 200$ LE MOIS
Le 05 décembre 2024 à 22:12:27 :
Maintenant 200, puis 2000, puis 20k, et dans 10 ans les IA accessibles seulement à ceux qui peuvent mettre 10 millions par mois
justement c'est l'inverse ahurin
le coût de l'inférence devient de moins en moins cher car les modèles sont plus performants tous les 3 mois
comme avec la loi de Moore
et les modèles open source deviennent meilleurs aussi
bref tu as raté une occasion de la fermer

Le 05 décembre 2024 à 22:37:04 :
Si tu cherches du open source et à garder tes donnés, Lm studio, c'est du local. Tu télécharges ensuite le modèle open-source que tu veux. Plus tu as un GPU puissant, plus tu peux faire fonctionner des modèles lourd et puissant. Et aussi, il faut de la ram.
C'est safe ? Je n'ai que 16Go et pas de GPU (c'est intégré à mon proc' quoi).
Ca marchera mais ça sera assez lent  enfin suivant le modèle d'IA que tu choisis
enfin suivant le modèle d'IA que tu choisis
Tu peux choisir des très petits qui seront moins perf mais qui répondront vite
Ici pour trouver les modèles que tu veux (faut prendre ceux en GGUF par contre)
https://huggingface.co/models
Le 05 décembre 2024 à 22:37:04 :
Si tu cherches du open source et à garder tes donnés, Lm studio, c'est du local. Tu télécharges ensuite le modèle open-source que tu veux. Plus tu as un GPU puissant, plus tu peux faire fonctionner des modèles lourd et puissant. Et aussi, il faut de la ram.
C'est safe ? Je n'ai que 16Go et pas de GPU (c'est intégré à mon proc' quoi).
j'ai un apple M4 + 16gb ca peut passer ?
j'ai un apple M4 + 16gb ca peut passer ?
Ça ne tourne pas sur du ARM je crois.
Le 05 décembre 2024 à 22:39:55 :
Quel modèle est efficace en local, et pas trop gourmand ? Je peux attendre deux minutes pour une réponse, hein.
tu installes ollama et tu lances llama3.2
ça fait le taff
Le 05 décembre 2024 à 22:39:55 :
Quel modèle est efficace en local, et pas trop gourmand ? Je peux attendre deux minutes pour une réponse, hein.
Pour un truc équivalent à ChatGPT, LLaMa 3.1 est top
La version 7b demande 8Go de vRAM par exemple
tu prends ollama et tu lances llama3.2
Ollama, c'est le modèle, et llama3.2, c'est la version ?
Le 05 décembre 2024 à 22:15:58 :
Le 05 décembre 2024 à 22:11:53 :
Le 05 décembre 2024 à 22:10:26 :
Le 05 décembre 2024 à 21:50:14 :
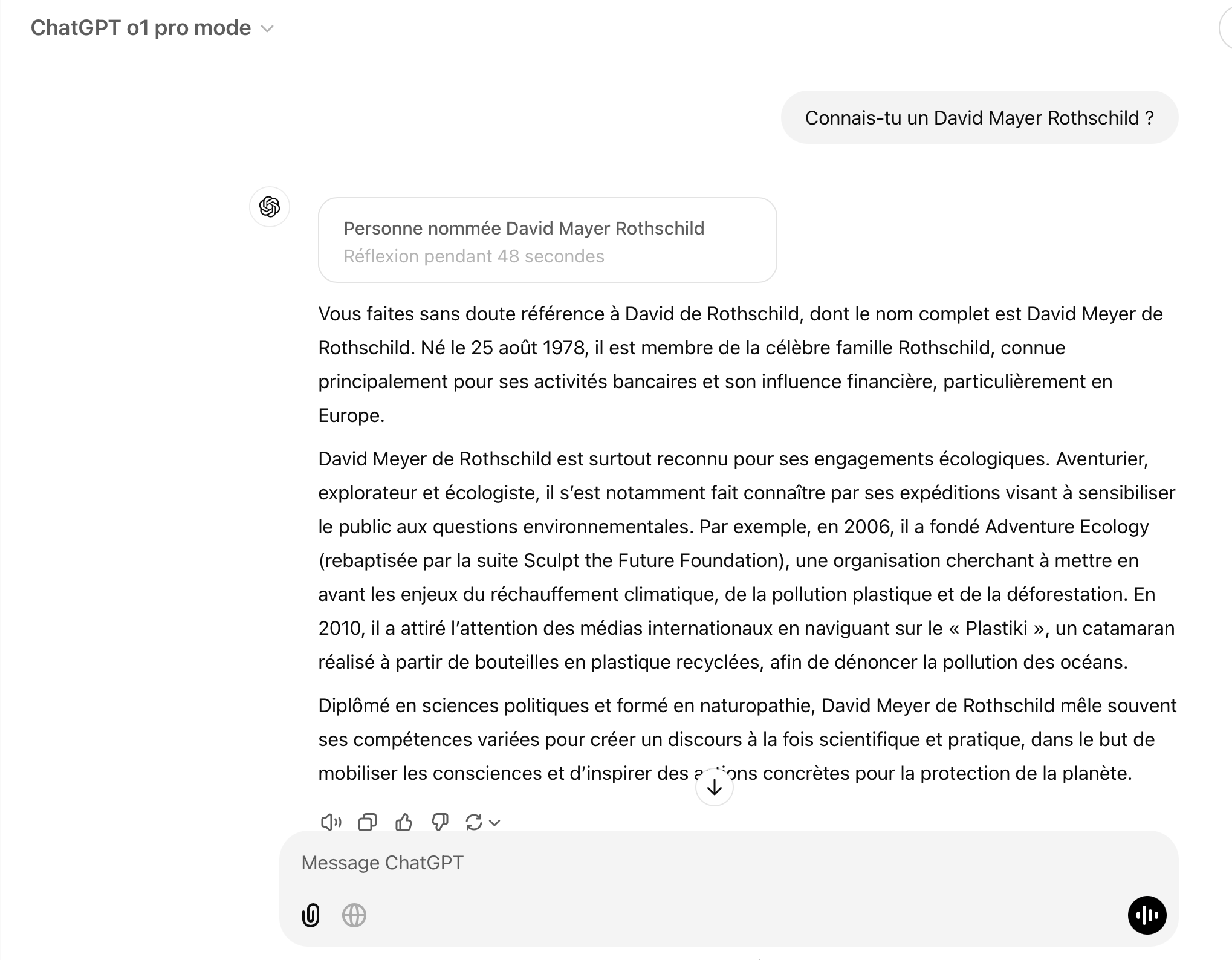
Demande lui qui est David Mayeril a répondu
Screen ou fake

incroyable, ça rajoute quelques clics en plus pour atteindre wikipédia 
Le 05 décembre 2024 à 21:50:14 :
Demande lui qui est David Mayer
Qui controle la meute mediatique ? le New York times, le Washinton post ?

https://gpt4all.io/index.html?ref=localhost
J'ai pas encore test, mais ça a l'air bien
Le 05 décembre 2024 à 22:42:04 :
tu prends ollama et tu lances llama3.2
Ollama, c'est le modèle, et llama3.2, c'est la version ?
non ollama c'est un client qui te permet de lancer des modèles open source localement
llama c'est le modèle et 3.2 la version car tua 3.2 billions parameters
tu as mistral de dispo aussi je crois, mais plus de paramètres donc faut une machine performante
tu peux aussi lancer ollama depuis un container docker je pense et le faire tourner sur une instance railway par exemple, comme ça ça tourne en permanence
La version 7b demande 8Go de vRAM par exemple
Moui, avec mon iGPU, c'est plié de ce côté-là je pense.
Le 05 décembre 2024 à 22:38:18 :
Le 05 décembre 2024 à 22:12:27 :
Maintenant 200, puis 2000, puis 20k, et dans 10 ans les IA accessibles seulement à ceux qui peuvent mettre 10 millions par moisjustement c'est l'inverse ahurin
le coût de l'inférence devient de moins en moins cher car les modèles sont plus performants tous les 3 mois
comme avec la loi de Moore
et les modèles open source deviennent meilleurs aussi
bref tu as raté une occasion de la fermer
Surtout qu'une IA n'a aucun intérêt à mettre de si grosse barrière à l'entrée, moins y'a de données utilisateurs et moins elles progressent
Par contre le prix pour les instance pro d'entreprise elles peuvent augmenter mais la version grand public ca restera accessible pour n'importe qui
Le 05 décembre 2024 à 22:42:39 :
https://gpt4all.io/index.html?ref=localhostJ'ai pas encore test, mais ça a l'air bien

Comme ça, ça vend un peu du rêve. Je suis à la masse sur l'IA bordel. Pourtant, je sais télécharger de la RAM.

Données du topic
- Auteur
- EnrichedUranium
- Date de création
- 5 décembre 2024 à 21:49:45
- Nb. messages archivés
- 67
- Nb. messages JVC
- 67