[IA] Tuto installer/utiliser stable diffusion pour générer des images !
Bonjour l'élite 
L'ancien topic datant d'il y a deux mois, et sa mise en forme n'étant pas parfaite, j'ai décidé de rédiger un tuto moi-même concernant cette ia, sur son installation et son utilisation 
.gif ":d)") C'est quoi ce truc, stable diffusion ?
C'est quoi ce truc, stable diffusion ?
Elle fonctionne à l'aide d'un modèle entrainé sur des millions d'images associées à des descriptions. Sur la quantité l'ia arrive à s'inspirer de tout ça et comprendre le concept derrière les mots et les illustrations pour par la suite faire de nouvelles images en suivant nos indications.
Il me faut une grosse config pour la faire tourner ? Sachez cependant que les cartes graphiques AMD sont fortement bridés sur l'ia, il est maintenant possible de faire fonctionner l'ia sans trop de mal (ce qui n'étais même pas le cas avant) mais les performances seront bien en dessous des cartes Nvidia !
Sachez cependant que les cartes graphiques AMD sont fortement bridés sur l'ia, il est maintenant possible de faire fonctionner l'ia sans trop de mal (ce qui n'étais même pas le cas avant) mais les performances seront bien en dessous des cartes Nvidia ! .gif ":g)")
A titre d'indication ça tourne sur une GTX 1060 6gb mais ça sera pas ultra rapide. Comptez une 15/20 secondes pour générer une image sur cette carte, en soi c'est pas tellement lent mais sur stable diffusion vous serez amené à enchainer les essais en retouchant votre description, un paramètre ou une autre variable qui pourrait améliorer le résultat. L'image sera pas forcément parfaite du premier coup. Mais ça reste très accessible quand-même
La quantité de vram à également son importance, celle-ci limitant la résolution de l'image et les possibles features que vous voudriez utiliser pour pousser le délire encore plus loin 
On recommande 8gb pour se mettre bien, mais sans être trop ambitieux 4gb suffisent à tâter l'ia. Autre exemple parlant pour la vram, vous devez savoir qu'il existe deux déclinaisons de la RTX 3060: la version normal avec 12gb de vram, et la version ti avec 8gb de vram. Cette gamme est une anomalie dans le sens où la version ti est plus puissante en jeu malgré sa plus faible vram, mais dans le cas de stable diffusion c'est la version normal 12gb qui est plus intéressante car bien que légèrement moins rapide sa plus grande vram permet de plus grandes possibilités de générations.
Pour finir prenez ce graphique 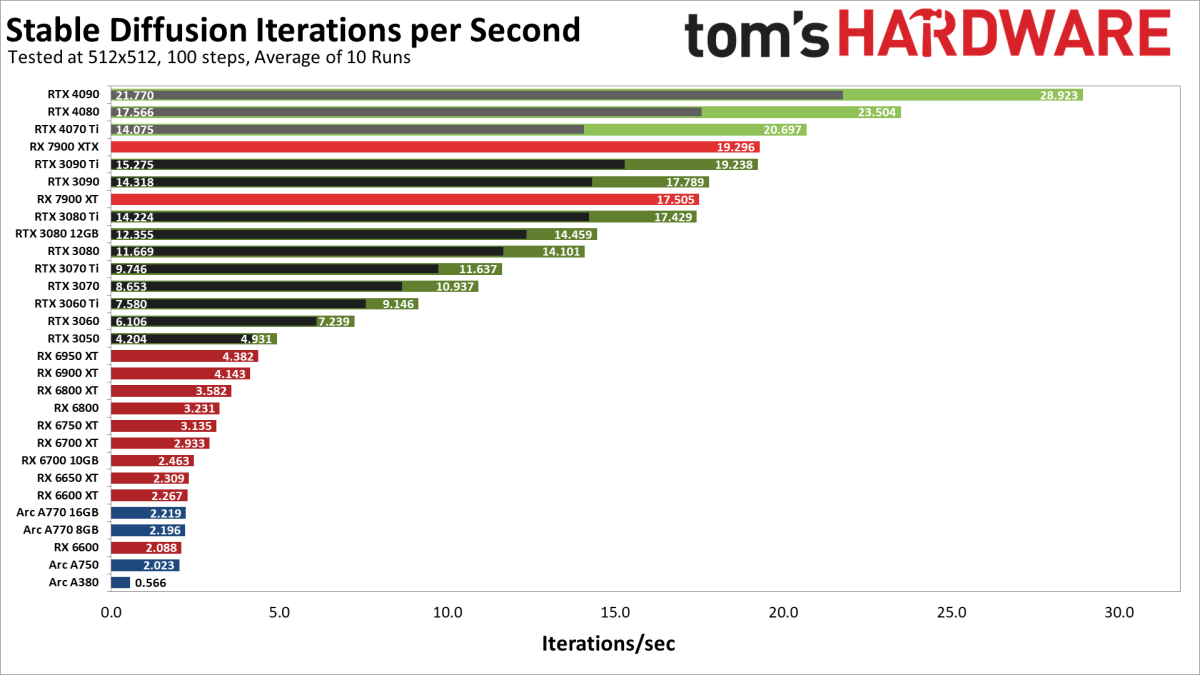 (les chiffres correspondent au nombre d'itérations par secondes, les itérations sont le nombres d'étapes que l'ia fait sur une image. Partez du principe qu'une image lambda fait 20 ou 30 étapes, pas moins)
(les chiffres correspondent au nombre d'itérations par secondes, les itérations sont le nombres d'étapes que l'ia fait sur une image. Partez du principe qu'une image lambda fait 20 ou 30 étapes, pas moins)
Passons maintenant à l'installation. N'ayez pas peur, c'est très simple. Il existe même des programme tout en un qui peuvent installer le truc d'un coup mais je préfère indiquer la méthode manuelle pour avoir une bonne installation propre comme tout le monde
Fichiers nécessaires à télécharger
-La dernière version de python 3.10 https://www.python.org/downloads/release/python-31010/ (tout en bas, dans files > Windows installer (64-bit)
-Un modèle pour le fonctionnement de l'ia https://huggingface.co/WarriorMama777/OrangeMixs/blob/main/Models/AbyssOrangeMix2/AbyssOrangeMix2_sfw.safetensors (cliquez sur download it au millieu) (je recommande ce modèle pour un style anime sympa mais vous pourrez par la suite en prendre d'autres)
-Un modèle "vae" https://huggingface.co/stabilityai/sd-vae-ft-mse-original/blob/main/vae-ft-mse-840000-ema-pruned.safetensors (pareil y'en a d'autres mais celui-ci est sympa et universel, vous verrez)
J'installe ça comment maintenant ?
Le tuto
-Faites un dossier dans votre PC où l'on pourra installer l'ia, je vous conseille à la racine du disque principal c'est plus pratique, vous pouvez le nommer comme vous voulez. Puis faites clic droit sur le dossier puis cliquez sur copier.
-Revenez sur git puis écrivez les deux lettres "cd", faites un espace puis faites un clic droit n'importe où dans git, enfin appuyez sur paste. ça va écrire le répertoire du dossier que vous venez de copier avant.
-Ecrivez (ou copiez c'est plus rapide ahi) la phrase suivante: "git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git" (sans les guillemets hein, et respectez l'espace entre git et clone, et entre clone et le lien)
.
ça va télécharger le noyau de l'ia, elle pèse pas lourd. C'est ce qu'on appelle l'interface web ce truc, elle gère le fonctionnement de l'ia et permettra son lancement sur votre navigateur internet.
.
-Ensuite dans ce dossier, vous pourrez aller ici \stable-diffusion-webui\models\Stable-diffusion et y foutre votre modèle de tout à l'heure, le truc abyssorangemix là. Mettez aussi le modèle vae ici \stable-diffusion-webui\models\VAE
.
Et c'est plus ou moins fini. Plus qu'à lancer le programme qui se chargera de finaliser l'installation, y'aura peut-être 2-3gb de téléchargement je sais plus exactement mais tout se fera tout seul lors du premier lancement du programme 
-Le programme à lancer est donc "webui-user.bat". Y'a deux webui-user dans le dossier de l'ia, un .bat et un .sh, c'est le .bat qu'il faut lancer, il pèse 1ko normalement.
Sachez que durant le premier lancement, comme il s'occupe d'installer ses trucs requis, ça peut parfois bloquer et prendre plusieurs minutes, c'est normal. Y'a pas forcément de barre de progression.
.
A la fin vous aurez une URL d'indiqué dans le programme, ça veut dire que l'ia est lancée. Foutez cette URL dans votre navigateur internet et l'ia se présentera devant vous  Résumé moins long du tuto , car j'ai tendance à m'étendre pour peu de choses.
Résumé moins long du tuto , car j'ai tendance à m'étendre pour peu de choses.
-Téléchargez un modèle au format safetensors pour l'ia, et un modèle vae aussi.
-Copiez le répertoire github "automatic1111" sur votre PC à l'aide de GIT.
-Dans ces nouveaux dossiers fraichement téléchargés, mettez vos deux modèles à l'endroit adéquat, simple à trouver.
-Lancez webui-user.bat, ça se termine tout seul et l'install est terminé.
Vous faites désormais partie de l'élite, l'ia est directement fonctionnel sur votre PC 
Dans mon prochain message je vais basiquement résumé les réglages disponible pour générer ses images dans l'interface de base. Et je conseillerais aussi certaines extensions de l'ia très sympa qui poussent le délire encore plus loin 
Vous voilà devant l'interface mais vous êtes un peu perdu, vous ne savez pas trop quoi faire pour laisser parler votre âme d'artiste ?  Explications des différents réglages principaux de l'interface pour générer des images. Onglet txt2img. Rien de bien complexe, c'est des infos pour les nouveaux qui débarquent dans le train.
Explications des différents réglages principaux de l'interface pour générer des images. Onglet txt2img. Rien de bien complexe, c'est des infos pour les nouveaux qui débarquent dans le train.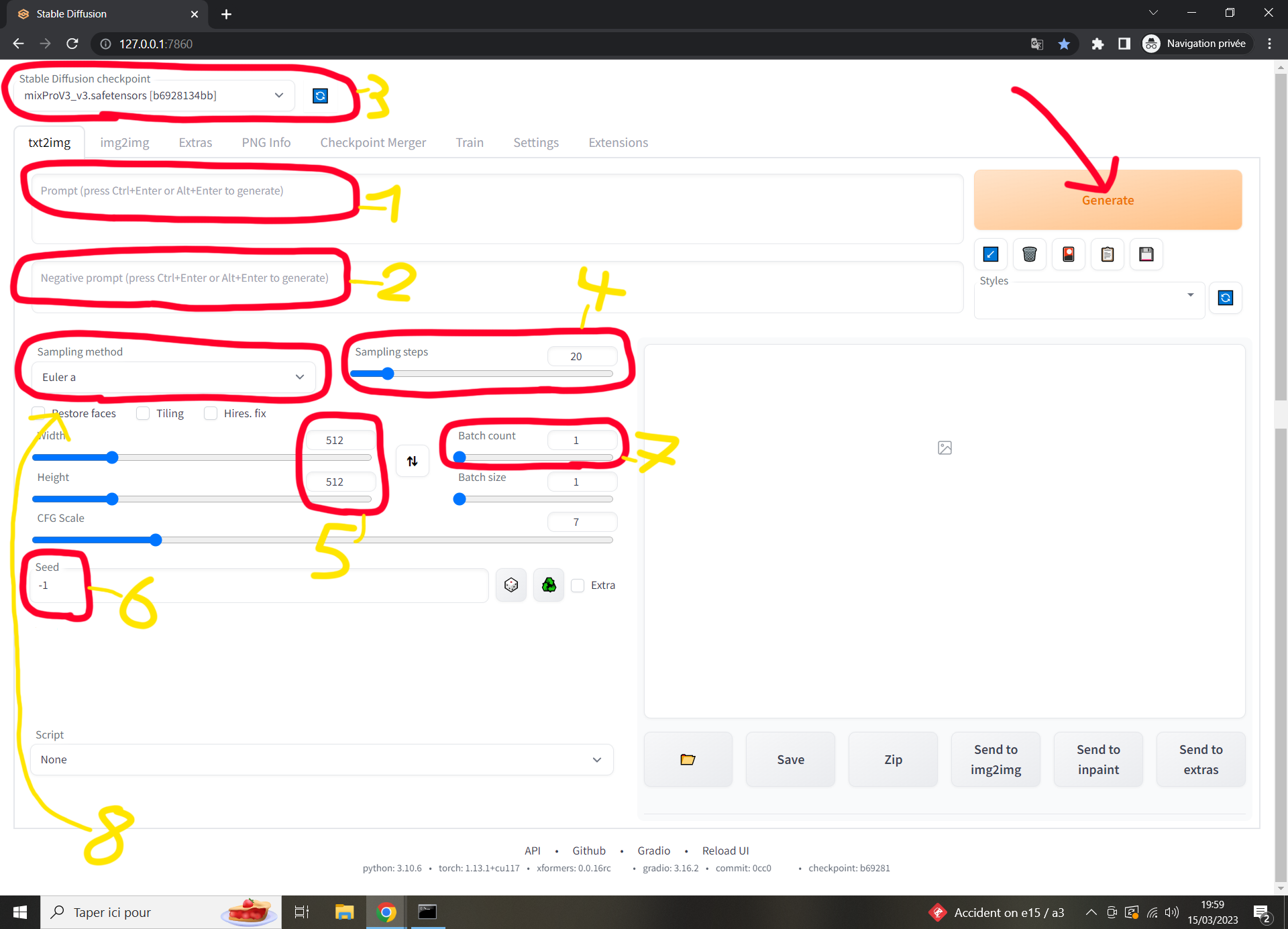
Il y a plusieurs onglets qui sont, dans l'ordre : txt2img, img2img, extras, PNG infos, checkpoint merger, train, settings et extensions. On va se contenter de celle de base aujourd'hui, à savoir txt2img qui permet de générer des images à partir de textes. Surprenant non ? 
J'ai classé les différents paramètres utiles par numéro sur mon image, on va rapidement les voir dans l'ordre.
1) Ce sont les prompts. Les mots indiqués pour la description. Sachez qu'il faut écrire en anglais mais utilisez le site deepl si vous avez du mal avec l'anglais, ça marche très bien.
Il y a plusieurs façons de s'exprimer à travers l'ia mais retenez que vos morceaux de phrases doivent être séparés par des virgules pour faire comprendre à l'ia que ce sont des prompts différents.
Une façon souvent utiliser d'écrire ses prompts est la suivante : Description du personnage, tags mis à la chaine pour clarifier son physique, description du background, d'autres tags pour clarifier certains détails dans la scènes, mots technique pour clarifier certains trucs finaux genre la qualité ou le style graphique etc.
Ce qui donne par exemple : Angry girl looking at the viewer, blond hair, short hair, yellow eyes, futuristic outfits, on a cyberpunk ship in space, sci-fi background, neon lights, galaxy, complex light, highly textured, best quality
J'entremêle des morceaux de phrases et des bêtes tags simplistes et séparés par des virgules.
Après je suis pas un pro, mais c'est ma façon de faire bien souvent 
2) Les prompts négatifs. C'est le même pricipe mais pour faire l'inverse, ça indique ce que vous ne voulez PAS voir sur votre image. Typiquement vous y foutez long hair (ce qui signifie cheveux longs, je suis bilingue) pour forcer le personnage à avoir des cheveux courts si l'indication dans les prompts normaux ne suffisait par par exemple.
3 C'est le modèle de l'ia. Stable diffusion fonctionne sur un système de modèle pour savoir comment générer ses images. Chaque modèle offre des résultats différents car ils ont été entrainé sur des bases de données d'images différentes ou conçu avec des paramètres différents tout simplement. Vous pouvez en mettre autant que vous voulez dans votre dossier, il apparaitra ici dans la liste déroulante que j'indique en numéro 3 sur le screen.
4) Les steps. C'est le nombre de "passage" au total que fait l'ia sur votre image pour la générer. 5 steps sont trop peu pour sortir un résultat ressemblant à quelque chose de bon, 30 steps représentent une bonne moyenne pour sortir un truc convainquant sans attendre une plombe et 200 steps sont parfois trop et l'image part en couille car de nombreux passages supplémentaires n'était pas nécessaire. Voyez la logique.
5) C'est la dimension de l'image. Je recommande de laisser en 512p512 pour une image carré, et de basculer l'un des deux champs en 768p512 pour sortir une image format 3:2 en paysage ou portrait. Vous pouvez monter plus haut pour sortir plus de détails mais ça sera plus lent et aussi gourmand sur votre carte graphique. Puis pour monter en résolution y'a aussi l'option hires. fix qui est sympa mais je prendrais pas le temps de l'expliquer ici.
6) La seed de l'image. Chaque seed donnera un résultat différent même si tous les autres paramètres ne changent pas. Le chiffre -1 correspond à l'aléatoire.
Pour ça que si vos prompts vous plaisent, vous pouvez enchainer les résultats jusqu'à tomber sur un rendu plus jolies que les précédents, et à ce moment vous pouvez si vous voulez recopier sa seed (écrite en bas de l'image fraichement générée) et la reprendre pour subtilement changer des paramètres pour garder la même image juste en la changeant un peu.
7) Le batch count, le nombre d'image que l'ia va générer à la suite lorsque vous cliquerez sur le bouton générer. Tout bêtement. Pratique si vous voulez laisser l'ia enchainer les générations pendant que vous faites quelque chose.
8) le sampleur. En gros c'est la méthode appliquée à l'ia pour générer son image depuis le début de la génération au fil des steps. Essayez avec plusieurs ça peut aussi changer un peu le style graphique. Certains sont assez similaires sinon, ça changera pas forcément grand-chose et la vitesse de génération peut parfois changer d'un sampleur à l'autre. Perso j'aime bien DPM++ 2M Karras. Y'a aussi le CFG scale qui est intéressant à manipuler mais flemme d'expliquer davantage, il est bien réglé de base. Retenez que vous êtes pas obligé de toucher à tout hein, écrivez juste vos prompts pour commencer et ça fonctionnera quand-même.
Aller plus loin et installer une extension à l'interface pour ajouter de nouvelles fonctionnalités.
Installer une extension
Chercher une extension qui vous plait, copiez son lien github dans l'onglet extension > install from url puis coller son lien github dans le champ correspondant et cliquez sur install. Une fois fini allez dans extension > installed puis cliquez sur Apply and restart UI. ça rechargera l'interface avec l'extension activée. C'est tout con.
Liste d'extensions que je recommande
Ça révolutionne stable diffusion bordel. En gros ça permet de capter certains éléments d'une image, pour l'appliquer lors de la génération d'une nouvelle image. Genre vous foutez la photo d'une personne et Controlnet est capable d'analyser sa pose pour l'appliquer à votre personnage. Ou bien vous prenez une image d'un paysage et ControlNet et capable d'analyser le contours des éléments qui la comporte pour reproduire une scène avec les mêmes dispositions, etc... C'est fou. https://youtu.be/KBYpYOfRt8M
-Latent couple https://github.com/opparco/stable-diffusion-webui-two-shot
Ça permet de diviser la zone de travail de l'image en deux pour appliquer différents prompts à différents endroits de l'image. https://youtu.be/WnZHNs1LqaA
-Image browser https://github.com/yfszzx/stable-diffusion-webui-images-browser
Rajoute un onglet pour voir toutes vos images générées depuis l'interface sans devoir fouiller dans vos dossiers.
-booru tagcomplete https://github.com/DominikDoom/a1111-sd-webui-tagcomplete
Vous propose de compléter vos prompts lorsque vous écrivez. Basé sur les sites boorus là, les galléries d'image anime quoi.
-webui ar https://github.com/alemelis/sd-webui-ar
Rajouter des boutons pour changer votre preset de résolution et l'adapter dans un format d'image genre 3:2, 16:9 etc...
Renseignez vous également sur les loras, c'est des petits fichier spécialement entrainé pour reproduire un personnage spécifique, des style/concepts graphiques... J'en profite pour vous balancer ce site https://civitai.com/
C'est une grosse base de données où les gens partagent des modèles, loras et autres trucs pour stable diffusion avec des galeries d'images en aperçu.
Cette page aussi https://rentry.org/54d9o qui montre plein d'images randoms (surtout des waifus) avec leurs prompts, de quoi s'inspirer sans vergogne si vous savez pas quoi écrire 
Je termine en précisant qu'on a un discord pour stable diffusion entre clés. On y discute de l'ia, on relaie les nouvelles infos puis on partage nos créations en s'entraidant quoi. Si ça vous intéresse dites-le pour qu'on vous file le lien en MP 

Le 15 mars 2023 à 23:28:00 :
Merci mon bon khey, je crois que ma consommation de mouchoir va exploser
Ah bah après tu fais comme tu veux hein, mais y'a de quoi se ruiner oui 
Ah j'ai oublié de préciser, faut sélectionner le vae dans l'onglet settings pour qu'il devienne actif. Allez dans settings > stable diffusion (dans la collone de gauche) puis vous verrez le champ pour sélectionner le vae que vous avez mis dans le dossier. Une fois sélectionné oubliez pas d'appuyer sur "apply settings" pour valider. ça restera comme ça par défaut pour les prochaines fois 
Complètement zinzolin l'IA.
Les "artistes" en ce moment

Le 15 mars 2023 à 23:37:58 :
Ouais faut avoir un pc a 2000 balles pour utiliser ton truc alors que ya midjourney pour 30 balles par mois
Une 1060 ça vaut 100 balles sur leboncoin, abuse pas non plus 
Le 15 mars 2023 à 23:38:56 :
Bordel, j'ai suivi le tuto et ma voici ma 1ere image

Complètement zinzolin l'IA.
Les "artistes" en ce moment
Impressionnant, après première image... 
Le 15 mars 2023 à 23:37:58 :
Ouais faut avoir un pc a 2000 balles pour utiliser ton truc alors que ya midjourney pour 30 balles par mois
Ayaa Midjourney.
Bien d'être le toutou d'une entreprise ? Ils contrôlent 100% de ce que tu fais.
Stable Diffusion c'est en local sur votre machine, 0 connection sur internet, 0 flicage.
Sauf que Midjourney t'a pas besoin de 300 choses à paramétrer et d'avoir un pc à 2000 balles
Un pc Auchan et tu sors des oeuvres d art
Le 15 mars 2023 à 23:42:59 :
Non ça tournera juste mais tu profitera pas de la pleine puissance de Stable
A ce moment tu prends une 3060 à 280 balles et là tu profites à fond de l'outil. Puissance très honorable et grosse quantité de vram pour pas être limité dans les fonctionnalités. C'est la carte parfaite pour stable 
Le 15 mars 2023 à 23:42:40 :
Le 15 mars 2023 à 23:37:58 :
Ouais faut avoir un pc a 2000 balles pour utiliser ton truc alors que ya midjourney pour 30 balles par moisAyaa Midjourney.
Bien d'être le toutou d'une entreprise ? Ils contrôlent 100% de ce que tu fais.
Stable Diffusion c'est en local sur votre machine, 0 connection sur internet, 0 flicage.
Tu peux vraiment lui demander ce que tu veux a l’ia si elle est utilisée en local ?
Même les trucs les plus tordus qui te passent par la tête elle va être capable de te pondre une image ?
T’as besoin d’internet pour la faire tourner ?
Le 15 mars 2023 à 23:46:33 :
Sauf que Midjourney t'a pas besoin de 300 choses à paramétrer et d'avoir un pc à 2000 ballesUn pc Auchan et tu sors des oeuvres d art
Sauf que c'est payant, sauf que c'est encadré, moins libre, sauf que c'est peut-être performant pour faire de jolies résultats mais ça propose peu d'options finalement, sauf que c'est pas local et que tu dois passer par internet/discord, sauf que tout en fait.
On va pas se mentir, midjourney sort des images de dingues. C'est la vérité. Mais c'est bien son seul atout, stable n'a que des avantages à côté. Puis le code source de stable est libre et gratuit, ça ne fait qu'évoluer tous les mois on a des trucs de dingue...
Le 15 mars 2023 à 23:50:06 :
Le 15 mars 2023 à 23:42:40 :
Le 15 mars 2023 à 23:37:58 :
Ouais faut avoir un pc a 2000 balles pour utiliser ton truc alors que ya midjourney pour 30 balles par moisAyaa Midjourney.
Bien d'être le toutou d'une entreprise ? Ils contrôlent 100% de ce que tu fais.
Stable Diffusion c'est en local sur votre machine, 0 connection sur internet, 0 flicage.Tu peux vraiment lui demander ce que tu veux a l’ia si elle est utilisé en local ?
Même les trucs les plus tordus qui te passent par la tête elle va être capable de te pondre une image ?
T’as besoin d’internet pour la faire tourner ?
Entièrement personalisable.
Surtout depuis décembre, on peut entrainer des modèles "loras" sur des personnages, concept, artstyle. Donc y a de tout dont des trucs sexuels ultra hardcore.
Exemple, le site Civitai qui est un site de partage de modèle pour Stable.
Au passage je mets le lien de mon profil avec mes modèles publiés :
https://civitai.com/user/Konan
Le 15 mars 2023 à 23:37:58 :
Ouais faut avoir un pc a 2000 balles pour utiliser ton truc alors que ya midjourney pour 30 balles par mois
Surtout que la V.5 est sortie aujourd'hui et est surement très au dessus de Stable Diffusion.
Après l'avantage, outre sa gratuité c'est la possibilité d'entrainer des modèles, de pouvoir modifier certaines parties de l'image et d'insérer des prompts négatifs
J'ai une NVIDIA GeForce RTX4060 8 Go
16 go ram
512 ssd
i7 12em gen
C'est mort pour moi ?
Le 15 mars 2023 à 23:53:23 :
J'ai une NVIDIA GeForce RTX4060 8 Go16 go ram
512 ssd
i7 12em gen
C'est mort pour moi ?
T'es fou ça passe largement, plein de gars font avec des cartes moins bonnes que toi
Le 15 mars 2023 à 23:51:49 :
Le 15 mars 2023 à 23:50:06 :
Le 15 mars 2023 à 23:42:40 :
Le 15 mars 2023 à 23:37:58 :
Ouais faut avoir un pc a 2000 balles pour utiliser ton truc alors que ya midjourney pour 30 balles par moisAyaa Midjourney.
Bien d'être le toutou d'une entreprise ? Ils contrôlent 100% de ce que tu fais.
Stable Diffusion c'est en local sur votre machine, 0 connection sur internet, 0 flicage.Tu peux vraiment lui demander ce que tu veux a l’ia si elle est utilisé en local ?
Même les trucs les plus tordus qui te passent par la tête elle va être capable de te pondre une image ?
T’as besoin d’internet pour la faire tourner ?
Entièrement personalisable.
Surtout depuis décembre, on peut entrainer des modèles "loras" sur des personnages, concept, artstyle. Donc y a de tout dont des trucs sexuels ultra hardcore.Exemple, le site Civitai qui est un site de partage de modèle pour Stable.
Au passage je mets le lien de mon profil avec mes modèles publiés :
https://civitai.com/user/Konan
Merci khey, j’ai un i5, une 980 gtx turbo et 32 go de mémoire. Je vais devoir changer de carte alors.
Données du topic
- Auteur
- KillerJamme
- Date de création
- 15 mars 2023 à 23:26:06
- Nb. messages archivés
- 462
- Nb. messages JVC
- 443