Un khey CALÉ en DEEP LEARNING? quelques questions

Du coup faut dropout pour réduire ce qui sert à rien? Je peux faire quoi de plus pour rendre ça moins douloureux?
Le 27 avril 2022 à 21:10:40 Saephyros a écrit :
Le 27 avril 2022 à 21:09:59 :
Le 27 avril 2022 à 21:05:41 Citranus a écrit :
Le 27 avril 2022 à 20:57:02 :
- ça existe déjà : dropout ça permet de renforcer la capacité d'apprentissage du réseau- autre façon de renforcer le message
- ça dépend de ce que tu veux faire, y a pas de "meilleur"
- Pytorch est plus utilisé en ce moment. Mais à ton niveau c'est pas important. Keras ça peut être un bon début
- C'est faisable, ça réduit le nombre de poids pour une même profondeur, donc ça réduit le temps d'entrainement. Le dropout, ce n'est pas ça.
-Ca s'appelle des couches parallèles, 'inception' je crois
-Il faut essayer pour savoir.
-Tensorflow/Keras et Pytorch ont les mêmes performances, c'est surtout la manière d'écrire le code qui change, effectivement keras est le plus simple.Je m'en fiche que ça soit dur niveau code tant que c'est LOGIQUE

en vrai de vrai pytorch est le plus pratique


bordel
je dois tout recommencer
Ce que ça fait, c'est que l'apprentissage est mieux réparti entre les neurones, et ça se voit au niveau des résultats.
Le 27 avril 2022 à 21:10:55 Citranus a écrit :
Le 27 avril 2022 à 21:08:03 :
Le 27 avril 2022 à 21:05:37 Saephyros a écrit :
Le 27 avril 2022 à 21:04:29 :
Apparemment le dropout c'est pas vraiment ça
Je demandais plus un truc comme ça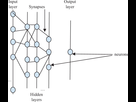
Ya un intérêt?Perso je suis ingé de recherche en deep mais pas claire ton schéma

bah à la couche 1 tu as 4 neurones avec 5 connexions pour 4 neurones à la couche 2 (au lieu de 16 connexions)
intérêt?L'intérêt c'est que pour arriver au résultat de ta couche de sortie, tu as peut être besoin de données qui ont déjà été calculées avant, si tu met un neurone là, il va juste reproduire une donnée, mais tu dépenseras du calcul pour ça, dis toi que chaque trait à l'entrée d'un neurone représente un gradient à calculer pour chaque batch d'entrée à chaque époque, moins il y en a plus ton réseau apprendra vite.

Ok donc l'intérêt c'est faire apprendre plus vite car moins de gradient à calculer
Mais du coup on sacrifie de la performance? Ou vu qu'il apprend plsu vite il est + performant?
Le 27 avril 2022 à 21:13:50 Citranus a écrit :
Le dropout bloque certains neurones choisis aléatoirement à chaque batch, c'est comme si on les retirait.
Ce que ça fait, c'est que l'apprentissage est mieux réparti entre les neurones, et ça se voit au niveau des résultats.
Mais si c'est aléatoire il peut supprimer des bons neurones?
On est pas censé les choisir?
Le 27 avril 2022 à 21:15:27 :
Le 27 avril 2022 à 21:10:55 Citranus a écrit :
Le 27 avril 2022 à 21:08:03 :
Le 27 avril 2022 à 21:05:37 Saephyros a écrit :
Le 27 avril 2022 à 21:04:29 :
Apparemment le dropout c'est pas vraiment ça
Je demandais plus un truc comme ça
Ya un intérêt?Perso je suis ingé de recherche en deep mais pas claire ton schéma
bah à la couche 1 tu as 4 neurones avec 5 connexions pour 4 neurones à la couche 2 (au lieu de 16 connexions)
intérêt?L'intérêt c'est que pour arriver au résultat de ta couche de sortie, tu as peut être besoin de données qui ont déjà été calculées avant, si tu met un neurone là, il va juste reproduire une donnée, mais tu dépenseras du calcul pour ça, dis toi que chaque trait à l'entrée d'un neurone représente un gradient à calculer pour chaque batch d'entrée à chaque époque, moins il y en a plus ton réseau apprendra vite.
Ok donc l'intérêt c'est faire apprendre plus vite car moins de gradient à calculer
Mais du coup on sacrifie de la performance? Ou vu qu'il apprend plsu vite il est + performant?
Je pense pas que tu puisses en attendre de meilleures performances en terme de qualité de prédiction.
Par contre, en performance en terme de rapidité d'entrainement, tu y gagnes.
Ce qu'il faut que tu comprennes, c'est que le deep learning, c'est surtout expérimental.
On a une idée, on la teste, si ça marche pas tant pis, sinon tant mieux.
Le 27 avril 2022 à 21:18:47 Citranus a écrit :
Le 27 avril 2022 à 21:15:27 :
Le 27 avril 2022 à 21:10:55 Citranus a écrit :
Le 27 avril 2022 à 21:08:03 :
Le 27 avril 2022 à 21:05:37 Saephyros a écrit :
Le 27 avril 2022 à 21:04:29 :
Apparemment le dropout c'est pas vraiment ça
Je demandais plus un truc comme ça
Ya un intérêt?Perso je suis ingé de recherche en deep mais pas claire ton schéma
bah à la couche 1 tu as 4 neurones avec 5 connexions pour 4 neurones à la couche 2 (au lieu de 16 connexions)
intérêt?L'intérêt c'est que pour arriver au résultat de ta couche de sortie, tu as peut être besoin de données qui ont déjà été calculées avant, si tu met un neurone là, il va juste reproduire une donnée, mais tu dépenseras du calcul pour ça, dis toi que chaque trait à l'entrée d'un neurone représente un gradient à calculer pour chaque batch d'entrée à chaque époque, moins il y en a plus ton réseau apprendra vite.
Ok donc l'intérêt c'est faire apprendre plus vite car moins de gradient à calculer
Mais du coup on sacrifie de la performance? Ou vu qu'il apprend plsu vite il est + performant?
Je pense pas que tu puisses en attendre de meilleures performances en terme de qualité de prédiction.
Par contre, en performance en terme de rapidité d'entrainement, tu y gagnes.Ce qu'il faut que tu comprennes, c'est que le deep learning, c'est surtout expérimental.
On a une idée, on la teste, si ça marche pas tant pis, sinon tant mieux.
Généralement ça prend combien de temps à entrainer un réseau? avec quelle puissance? de façon classique on va dire
Le 27 avril 2022 à 21:18:14 :
Le 27 avril 2022 à 21:13:50 Citranus a écrit :
Le dropout bloque certains neurones choisis aléatoirement à chaque batch, c'est comme si on les retirait.
Ce que ça fait, c'est que l'apprentissage est mieux réparti entre les neurones, et ça se voit au niveau des résultats.Mais si c'est aléatoire il peut supprimer des bons neurones?
On est pas censé les choisir?
Il supprime aussi les bons neurones, cela force d'autres neurones à remplir son rôle, c'est ce qui fait que le dropout est efficace : le réseau ne dépend pas d'un seul neurone.
Le 27 avril 2022 à 21:20:52 Citranus a écrit :
Le 27 avril 2022 à 21:18:14 :
Le 27 avril 2022 à 21:13:50 Citranus a écrit :
Le dropout bloque certains neurones choisis aléatoirement à chaque batch, c'est comme si on les retirait.
Ce que ça fait, c'est que l'apprentissage est mieux réparti entre les neurones, et ça se voit au niveau des résultats.Mais si c'est aléatoire il peut supprimer des bons neurones?
On est pas censé les choisir?Il supprime aussi les bons neurones, cela force d'autres neurones à remplir son rôle, c'est ce qui fait que le dropout est efficace : le réseau ne dépend pas d'un seul neurone.
Est ce vraiment une mauvaise chose?
Ton cerveau ya des régions plus importantes que d'autres, si on te les retire ton cerveau marche plus
Pourquoi ça serait pas la même là?
Le 27 avril 2022 à 21:19:45 :
Le 27 avril 2022 à 21:18:47 Citranus a écrit :
Le 27 avril 2022 à 21:15:27 :
Le 27 avril 2022 à 21:10:55 Citranus a écrit :
Le 27 avril 2022 à 21:08:03 :
Le 27 avril 2022 à 21:05:37 Saephyros a écrit :
Le 27 avril 2022 à 21:04:29 :
Apparemment le dropout c'est pas vraiment ça
Je demandais plus un truc comme ça
Ya un intérêt?Perso je suis ingé de recherche en deep mais pas claire ton schéma
bah à la couche 1 tu as 4 neurones avec 5 connexions pour 4 neurones à la couche 2 (au lieu de 16 connexions)
intérêt?L'intérêt c'est que pour arriver au résultat de ta couche de sortie, tu as peut être besoin de données qui ont déjà été calculées avant, si tu met un neurone là, il va juste reproduire une donnée, mais tu dépenseras du calcul pour ça, dis toi que chaque trait à l'entrée d'un neurone représente un gradient à calculer pour chaque batch d'entrée à chaque époque, moins il y en a plus ton réseau apprendra vite.
Ok donc l'intérêt c'est faire apprendre plus vite car moins de gradient à calculer
Mais du coup on sacrifie de la performance? Ou vu qu'il apprend plsu vite il est + performant?
Je pense pas que tu puisses en attendre de meilleures performances en terme de qualité de prédiction.
Par contre, en performance en terme de rapidité d'entrainement, tu y gagnes.Ce qu'il faut que tu comprennes, c'est que le deep learning, c'est surtout expérimental.
On a une idée, on la teste, si ça marche pas tant pis, sinon tant mieux.Généralement ça prend combien de temps à entrainer un réseau? avec quelle puissance? de façon classique on va dire
Tout dépend du réseau. Par contre si tu t'y intéresses vraiment khey je te donne un bon conseil, achète-toi un bon PC de gamer avec un GPU nvidia.
Tu pourras jouer à des super FPS et en plus tu as ce qu'on appelle Cuda, tu utilises la carte graphique pour entraîner ton réseau et ça va infiniment plus vite.
Ah, et niveau outils, je te conseille vivement d'utiliser jupyterlab pour coder.
Le 27 avril 2022 à 21:23:52 ploud4 a écrit :
Le 27 avril 2022 à 21:19:45 :
Le 27 avril 2022 à 21:18:47 Citranus a écrit :
Le 27 avril 2022 à 21:15:27 :
Le 27 avril 2022 à 21:10:55 Citranus a écrit :
Le 27 avril 2022 à 21:08:03 :
Le 27 avril 2022 à 21:05:37 Saephyros a écrit :
Le 27 avril 2022 à 21:04:29 :
Apparemment le dropout c'est pas vraiment ça
Je demandais plus un truc comme ça
Ya un intérêt?Perso je suis ingé de recherche en deep mais pas claire ton schéma
bah à la couche 1 tu as 4 neurones avec 5 connexions pour 4 neurones à la couche 2 (au lieu de 16 connexions)
intérêt?L'intérêt c'est que pour arriver au résultat de ta couche de sortie, tu as peut être besoin de données qui ont déjà été calculées avant, si tu met un neurone là, il va juste reproduire une donnée, mais tu dépenseras du calcul pour ça, dis toi que chaque trait à l'entrée d'un neurone représente un gradient à calculer pour chaque batch d'entrée à chaque époque, moins il y en a plus ton réseau apprendra vite.
Ok donc l'intérêt c'est faire apprendre plus vite car moins de gradient à calculer
Mais du coup on sacrifie de la performance? Ou vu qu'il apprend plsu vite il est + performant?
Je pense pas que tu puisses en attendre de meilleures performances en terme de qualité de prédiction.
Par contre, en performance en terme de rapidité d'entrainement, tu y gagnes.Ce qu'il faut que tu comprennes, c'est que le deep learning, c'est surtout expérimental.
On a une idée, on la teste, si ça marche pas tant pis, sinon tant mieux.Généralement ça prend combien de temps à entrainer un réseau? avec quelle puissance? de façon classique on va dire
Tout dépend du réseau. Par contre si tu t'y intéresses vraiment khey je te donne un bon conseil, achète-toi un bon PC de gamer avec un GPU nvidia.
Tu pourras jouer à des super FPS et en plus tu as ce qu'on appelle Cuda, tu utilises la carte graphique pour entraîner ton réseau et ça va infiniment plus vite.
Ah, et niveau outils, je te conseille vivement d'utiliser jupyterlab pour coder.
J'ai un pc correct heureusement
Cuda j'ai vite vu ce que c'était pendant que je cherchais quoi installer mais j'ai pas trop compris
Ah bah faut savoir l'autre khey déconseille, il apporte quoi de plus? sachant que j'ai déjà test c'est trop bizarre avec les cellules
Le 27 avril 2022 à 21:22:33 :
Le 27 avril 2022 à 21:20:52 Citranus a écrit :
Le 27 avril 2022 à 21:18:14 :
Le 27 avril 2022 à 21:13:50 Citranus a écrit :
Le dropout bloque certains neurones choisis aléatoirement à chaque batch, c'est comme si on les retirait.
Ce que ça fait, c'est que l'apprentissage est mieux réparti entre les neurones, et ça se voit au niveau des résultats.Mais si c'est aléatoire il peut supprimer des bons neurones?
On est pas censé les choisir?Il supprime aussi les bons neurones, cela force d'autres neurones à remplir son rôle, c'est ce qui fait que le dropout est efficace : le réseau ne dépend pas d'un seul neurone.
Est ce vraiment une mauvaise chose?
Ton cerveau ya des régions plus importantes que d'autres, si on te les retire ton cerveau marche plus
Pourquoi ça serait pas la même là?
Le cerveau humain est capable de réutiliser d'autres zones pour compenser des zones qui ne fonctionnent plus, l'idée c'est que ton réseau de neurones soit pareil.
Mais je pense que tu vas peut-être un peu vite en besogne, avant de faire des réseaux de neurones ce serait déjà bien que tu saches faire de l'apprentissage plus basique. Est-ce que tu sais entraîner un arbre de décision ? Un knn ? Une régression linéaire ? Une régression logistique ? Tout ça ça te parle ?
Je sais que les réseaux de neurones c'est à la mode en ce moment, mais faut connaître les bases. Souvent les modèles plus simples sont meilleurs, j'ai déjà eu le cas.
Le 27 avril 2022 à 21:25:09 :
Le 27 avril 2022 à 21:23:52 ploud4 a écrit :
Le 27 avril 2022 à 21:19:45 :
Le 27 avril 2022 à 21:18:47 Citranus a écrit :
Le 27 avril 2022 à 21:15:27 :
Le 27 avril 2022 à 21:10:55 Citranus a écrit :
Le 27 avril 2022 à 21:08:03 :
Le 27 avril 2022 à 21:05:37 Saephyros a écrit :
Le 27 avril 2022 à 21:04:29 :
Apparemment le dropout c'est pas vraiment ça
Je demandais plus un truc comme ça
Ya un intérêt?Perso je suis ingé de recherche en deep mais pas claire ton schéma
bah à la couche 1 tu as 4 neurones avec 5 connexions pour 4 neurones à la couche 2 (au lieu de 16 connexions)
intérêt?L'intérêt c'est que pour arriver au résultat de ta couche de sortie, tu as peut être besoin de données qui ont déjà été calculées avant, si tu met un neurone là, il va juste reproduire une donnée, mais tu dépenseras du calcul pour ça, dis toi que chaque trait à l'entrée d'un neurone représente un gradient à calculer pour chaque batch d'entrée à chaque époque, moins il y en a plus ton réseau apprendra vite.
Ok donc l'intérêt c'est faire apprendre plus vite car moins de gradient à calculer
Mais du coup on sacrifie de la performance? Ou vu qu'il apprend plsu vite il est + performant?
Je pense pas que tu puisses en attendre de meilleures performances en terme de qualité de prédiction.
Par contre, en performance en terme de rapidité d'entrainement, tu y gagnes.Ce qu'il faut que tu comprennes, c'est que le deep learning, c'est surtout expérimental.
On a une idée, on la teste, si ça marche pas tant pis, sinon tant mieux.Généralement ça prend combien de temps à entrainer un réseau? avec quelle puissance? de façon classique on va dire
Tout dépend du réseau. Par contre si tu t'y intéresses vraiment khey je te donne un bon conseil, achète-toi un bon PC de gamer avec un GPU nvidia.
Tu pourras jouer à des super FPS et en plus tu as ce qu'on appelle Cuda, tu utilises la carte graphique pour entraîner ton réseau et ça va infiniment plus vite.
Ah, et niveau outils, je te conseille vivement d'utiliser jupyterlab pour coder.
J'ai un pc correct heureusement
Cuda j'ai vite vu ce que c'était pendant que je cherchais quoi installer mais j'ai pas trop compris
Ah bah faut savoir l'autre khey déconseille, il apporte quoi de plus? sachant que j'ai déjà test c'est trop bizarre avec les cellules
Tout le monde utilise ça en ML. N'écoute pas l'autre qui te conseille d'utiliser vim, c'est un troll, Vim c'est un éditeur pour les puristes de la console sous Linux qui est pas intuitif du tout et ça te prend des mois avant de savoir l'exécuter.
L'avantage avec les cellules c'est que tu peux afficher facilement des graphes, des tables... Bref tout ce dont un bon statisticien a besoin. Car oui, un ingé ML est un statisticien avant tout.
Le 27 avril 2022 à 20:54:28 :
- Dans les models chaque neurons d'une couche sont reliés à tous les autres neurons de la coucheX+1, mais est ce qu'on pourrait pas faire un nombre de connexions aléatoires? ça a un intérêt? un nom?- Apparemment ya des réseaux où une couche saute la coucheX+1 pour aller sur une autre encore plus loin, encore : nom ? intérêt?
- Le meilleur système pour du deeplearning en finance (analyse de chart et prédiction) c'est quoi? CNN? LSTMN?
- Tensorflow le meilleur pour faire ça?
Je travaille dans le domaine et je ne peux répondre à aucune de tes questions 
Le 27 avril 2022 à 21:22:33 :
Le 27 avril 2022 à 21:20:52 Citranus a écrit :
Le 27 avril 2022 à 21:18:14 :
Le 27 avril 2022 à 21:13:50 Citranus a écrit :
Le dropout bloque certains neurones choisis aléatoirement à chaque batch, c'est comme si on les retirait.
Ce que ça fait, c'est que l'apprentissage est mieux réparti entre les neurones, et ça se voit au niveau des résultats.Mais si c'est aléatoire il peut supprimer des bons neurones?
On est pas censé les choisir?Il supprime aussi les bons neurones, cela force d'autres neurones à remplir son rôle, c'est ce qui fait que le dropout est efficace : le réseau ne dépend pas d'un seul neurone.
Est ce vraiment une mauvaise chose?
Ton cerveau ya des régions plus importantes que d'autres, si on te les retire ton cerveau marche plus
Pourquoi ça serait pas la même là?
Si on retire des zones de ton cerveau, il peut aussi s'adapter pour que des neurones prennent la place de ceux que tu as détruit.
Là on retire une partie aléatoire des neurones à chaque fois, c'est pas pareil.
Le 27 avril 2022 à 21:25:57 ploud4 a écrit :
Le 27 avril 2022 à 21:22:33 :
Le 27 avril 2022 à 21:20:52 Citranus a écrit :
Le 27 avril 2022 à 21:18:14 :
Le 27 avril 2022 à 21:13:50 Citranus a écrit :
Le dropout bloque certains neurones choisis aléatoirement à chaque batch, c'est comme si on les retirait.
Ce que ça fait, c'est que l'apprentissage est mieux réparti entre les neurones, et ça se voit au niveau des résultats.Mais si c'est aléatoire il peut supprimer des bons neurones?
On est pas censé les choisir?Il supprime aussi les bons neurones, cela force d'autres neurones à remplir son rôle, c'est ce qui fait que le dropout est efficace : le réseau ne dépend pas d'un seul neurone.
Est ce vraiment une mauvaise chose?
Ton cerveau ya des régions plus importantes que d'autres, si on te les retire ton cerveau marche plus
Pourquoi ça serait pas la même là?Le cerveau humain est capable de réutiliser d'autres zones pour compenser des zones qui ne fonctionnent plus, l'idée c'est que ton réseau de neurones soit pareil.
Mais je pense que tu vas peut-être un peu vite en besogne, avant de faire des réseaux de neurones ce serait déjà bien que tu saches faire de l'apprentissage plus basique. Est-ce que tu sais entraîner un arbre de décision ? Un knn ? Une régression linéaire ? Une régression logistique ? Tout ça ça te parle ?
Je sais que les réseaux de neurones c'est à la mode en ce moment, mais faut connaître les bases. Souvent les modèles plus simples sont meilleurs, j'ai déjà eu le cas.
Je pense que c'est le plus adapté vu la quantité de données que j'ai à traiter, et vu la nature des marchés financiers
Celui qui a créé ça est un genius
Le 27 avril 2022 à 21:27:15 ploud4 a écrit :
Le 27 avril 2022 à 21:25:09 :
Le 27 avril 2022 à 21:23:52 ploud4 a écrit :
Le 27 avril 2022 à 21:19:45 :
Le 27 avril 2022 à 21:18:47 Citranus a écrit :
Le 27 avril 2022 à 21:15:27 :
Le 27 avril 2022 à 21:10:55 Citranus a écrit :
Le 27 avril 2022 à 21:08:03 :
Le 27 avril 2022 à 21:05:37 Saephyros a écrit :
Le 27 avril 2022 à 21:04:29 :
Apparemment le dropout c'est pas vraiment ça
Je demandais plus un truc comme ça
Ya un intérêt?Perso je suis ingé de recherche en deep mais pas claire ton schéma
bah à la couche 1 tu as 4 neurones avec 5 connexions pour 4 neurones à la couche 2 (au lieu de 16 connexions)
intérêt?L'intérêt c'est que pour arriver au résultat de ta couche de sortie, tu as peut être besoin de données qui ont déjà été calculées avant, si tu met un neurone là, il va juste reproduire une donnée, mais tu dépenseras du calcul pour ça, dis toi que chaque trait à l'entrée d'un neurone représente un gradient à calculer pour chaque batch d'entrée à chaque époque, moins il y en a plus ton réseau apprendra vite.
Ok donc l'intérêt c'est faire apprendre plus vite car moins de gradient à calculer
Mais du coup on sacrifie de la performance? Ou vu qu'il apprend plsu vite il est + performant?
Je pense pas que tu puisses en attendre de meilleures performances en terme de qualité de prédiction.
Par contre, en performance en terme de rapidité d'entrainement, tu y gagnes.Ce qu'il faut que tu comprennes, c'est que le deep learning, c'est surtout expérimental.
On a une idée, on la teste, si ça marche pas tant pis, sinon tant mieux.Généralement ça prend combien de temps à entrainer un réseau? avec quelle puissance? de façon classique on va dire
Tout dépend du réseau. Par contre si tu t'y intéresses vraiment khey je te donne un bon conseil, achète-toi un bon PC de gamer avec un GPU nvidia.
Tu pourras jouer à des super FPS et en plus tu as ce qu'on appelle Cuda, tu utilises la carte graphique pour entraîner ton réseau et ça va infiniment plus vite.
Ah, et niveau outils, je te conseille vivement d'utiliser jupyterlab pour coder.
J'ai un pc correct heureusement
Cuda j'ai vite vu ce que c'était pendant que je cherchais quoi installer mais j'ai pas trop compris
Ah bah faut savoir l'autre khey déconseille, il apporte quoi de plus? sachant que j'ai déjà test c'est trop bizarre avec les cellulesTout le monde utilise ça en ML. N'écoute pas l'autre qui te conseille d'utiliser vim, c'est un troll, Vim c'est un éditeur pour les puristes de la console sous Linux qui est pas intuitif du tout et ça te prend des mois avant de savoir l'exécuter.
L'avantage avec les cellules c'est que tu peux afficher facilement des graphes, des tables... Bref tout ce dont un bon statisticien a besoin. Car oui, un ingé ML est un statisticien avant tout.
Ah bah justement c'est pas possible avec pycharm les graph?
Le 27 avril 2022 à 21:30:26 :
Le 27 avril 2022 à 21:25:57 ploud4 a écrit :
Le 27 avril 2022 à 21:22:33 :
Le 27 avril 2022 à 21:20:52 Citranus a écrit :
Le 27 avril 2022 à 21:18:14 :
Le 27 avril 2022 à 21:13:50 Citranus a écrit :
Le dropout bloque certains neurones choisis aléatoirement à chaque batch, c'est comme si on les retirait.
Ce que ça fait, c'est que l'apprentissage est mieux réparti entre les neurones, et ça se voit au niveau des résultats.Mais si c'est aléatoire il peut supprimer des bons neurones?
On est pas censé les choisir?Il supprime aussi les bons neurones, cela force d'autres neurones à remplir son rôle, c'est ce qui fait que le dropout est efficace : le réseau ne dépend pas d'un seul neurone.
Est ce vraiment une mauvaise chose?
Ton cerveau ya des régions plus importantes que d'autres, si on te les retire ton cerveau marche plus
Pourquoi ça serait pas la même là?Le cerveau humain est capable de réutiliser d'autres zones pour compenser des zones qui ne fonctionnent plus, l'idée c'est que ton réseau de neurones soit pareil.
Mais je pense que tu vas peut-être un peu vite en besogne, avant de faire des réseaux de neurones ce serait déjà bien que tu saches faire de l'apprentissage plus basique. Est-ce que tu sais entraîner un arbre de décision ? Un knn ? Une régression linéaire ? Une régression logistique ? Tout ça ça te parle ?
Je sais que les réseaux de neurones c'est à la mode en ce moment, mais faut connaître les bases. Souvent les modèles plus simples sont meilleurs, j'ai déjà eu le cas.
Je pense que c'est le plus adapté vu la quantité de données que j'ai à traiter, et vu la nature des marchés financiers

Khey comment tu peux savoir, tu as même pas testé.
Le 27 avril 2022 à 21:31:19 :
Le 27 avril 2022 à 21:27:15 ploud4 a écrit :
Le 27 avril 2022 à 21:25:09 :
Le 27 avril 2022 à 21:23:52 ploud4 a écrit :
Le 27 avril 2022 à 21:19:45 :
Le 27 avril 2022 à 21:18:47 Citranus a écrit :
Le 27 avril 2022 à 21:15:27 :
Le 27 avril 2022 à 21:10:55 Citranus a écrit :
Le 27 avril 2022 à 21:08:03 :
Le 27 avril 2022 à 21:05:37 Saephyros a écrit :
Le 27 avril 2022 à 21:04:29 :
Apparemment le dropout c'est pas vraiment ça
Je demandais plus un truc comme ça
Ya un intérêt?Perso je suis ingé de recherche en deep mais pas claire ton schéma
bah à la couche 1 tu as 4 neurones avec 5 connexions pour 4 neurones à la couche 2 (au lieu de 16 connexions)
intérêt?L'intérêt c'est que pour arriver au résultat de ta couche de sortie, tu as peut être besoin de données qui ont déjà été calculées avant, si tu met un neurone là, il va juste reproduire une donnée, mais tu dépenseras du calcul pour ça, dis toi que chaque trait à l'entrée d'un neurone représente un gradient à calculer pour chaque batch d'entrée à chaque époque, moins il y en a plus ton réseau apprendra vite.
Ok donc l'intérêt c'est faire apprendre plus vite car moins de gradient à calculer
Mais du coup on sacrifie de la performance? Ou vu qu'il apprend plsu vite il est + performant?
Je pense pas que tu puisses en attendre de meilleures performances en terme de qualité de prédiction.
Par contre, en performance en terme de rapidité d'entrainement, tu y gagnes.Ce qu'il faut que tu comprennes, c'est que le deep learning, c'est surtout expérimental.
On a une idée, on la teste, si ça marche pas tant pis, sinon tant mieux.Généralement ça prend combien de temps à entrainer un réseau? avec quelle puissance? de façon classique on va dire
Tout dépend du réseau. Par contre si tu t'y intéresses vraiment khey je te donne un bon conseil, achète-toi un bon PC de gamer avec un GPU nvidia.
Tu pourras jouer à des super FPS et en plus tu as ce qu'on appelle Cuda, tu utilises la carte graphique pour entraîner ton réseau et ça va infiniment plus vite.
Ah, et niveau outils, je te conseille vivement d'utiliser jupyterlab pour coder.
J'ai un pc correct heureusement
Cuda j'ai vite vu ce que c'était pendant que je cherchais quoi installer mais j'ai pas trop compris
Ah bah faut savoir l'autre khey déconseille, il apporte quoi de plus? sachant que j'ai déjà test c'est trop bizarre avec les cellulesTout le monde utilise ça en ML. N'écoute pas l'autre qui te conseille d'utiliser vim, c'est un troll, Vim c'est un éditeur pour les puristes de la console sous Linux qui est pas intuitif du tout et ça te prend des mois avant de savoir l'exécuter.
L'avantage avec les cellules c'est que tu peux afficher facilement des graphes, des tables... Bref tout ce dont un bon statisticien a besoin. Car oui, un ingé ML est un statisticien avant tout.
Ah bah justement c'est pas possible avec pycharm les graph?
Non, Pycharm c'est un éditeur de code pour les gros projets, si tu veux exécuter des notebooks dedans tu peux mais faut raquer la version payante.
Données du topic
- Auteur
- HunterChasseur
- Date de création
- 27 avril 2022 à 20:54:28
- Nb. messages archivés
- 257
- Nb. messages JVC
- 245