Un khey CALÉ en DEEP LEARNING? quelques questions
- Dans les models chaque neurons d'une couche sont reliés à tous les autres neurons de la coucheX+1, mais est ce qu'on pourrait pas faire un nombre de connexions aléatoires? ça a un intérêt? un nom? 
- Apparemment ya des réseaux où une couche saute la coucheX+1 pour aller sur une autre encore plus loin, encore : nom ? intérêt?
- Le meilleur système pour du deeplearning en finance (analyse de chart et prédiction) c'est quoi? CNN? LSTMN?
- Tensorflow le meilleur pour faire ça?
- ça existe déjà : dropout ça permet de renforcer la capacité d'apprentissage du réseau
- autre façon de renforcer le message
- ça dépend de ce que tu veux faire, y a pas de "meilleur"
- Pytorch est plus utilisé en ce moment. Mais à ton niveau c'est pas important. Keras ça peut être un bon début
Le 27 avril 2022 à 20:57:02 Yellowdgis a écrit :
- ça existe déjà : dropout ça permet de renforcer la capacité d'apprentissage du réseau- autre façon de renforcer le message
- ça dépend de ce que tu veux faire, y a pas de "meilleur"
- Pytorch est plus utilisé en ce moment. Mais à ton niveau c'est pas important. Keras ça peut être un bon début
mais comment ça renforce sachant que les données sont moins traitées?
Bah analyse de chart et prédiction de prix de stocks / crypto
Je suis sur tensorflow avec pycharm, je pars de 0
Le 27 avril 2022 à 20:58:15 Yellowdgis a écrit :
Je développe pas parce que je suis sur mon tél. Mais un kheyou viendra sûrement t'aider si ce n'est moi plus tard sur pc
Ah bah j'attends avec impatience, je fav le topic pour pas rater, si c'est 410 hésite pas à MP
.gif ":)")
Vim te sera suffisant

Le 27 avril 2022 à 21:00:50 Saephyros a écrit :
delete pycharm déjà
Vim te sera suffisant
Explication peut être?
Il a quoi pycharm ?

Je demandais plus un truc comme ça
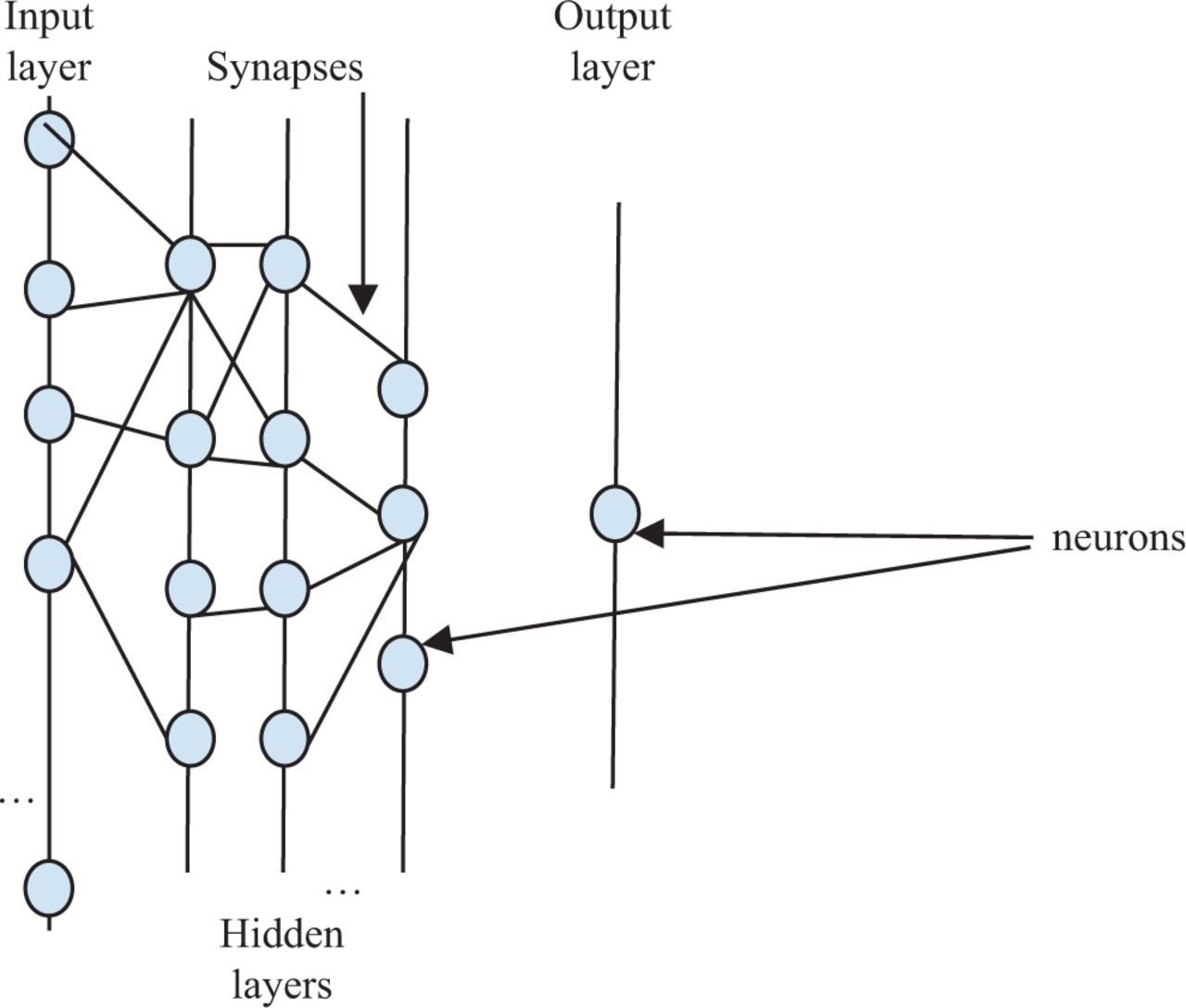
Ya un intérêt?
Le 27 avril 2022 à 21:04:29 :
Apparemment le dropout c'est pas vraiment ça
Je demandais plus un truc comme ça
Ya un intérêt?
Perso je suis ingé de recherche en deep mais pas claire ton schéma 
Le 27 avril 2022 à 20:57:02 :
- ça existe déjà : dropout ça permet de renforcer la capacité d'apprentissage du réseau- autre façon de renforcer le message
- ça dépend de ce que tu veux faire, y a pas de "meilleur"
- Pytorch est plus utilisé en ce moment. Mais à ton niveau c'est pas important. Keras ça peut être un bon début
- C'est faisable, ça réduit le nombre de poids pour une même profondeur, donc ça réduit le temps d'entrainement. Le dropout, ce n'est pas ça.
-Ca s'appelle des couches parallèles, 'inception' je crois
-Il faut essayer pour savoir.
-Tensorflow/Keras et Pytorch ont les mêmes performances, c'est surtout la manière d'écrire le code qui change, effectivement keras est le plus simple.
Le 27 avril 2022 à 21:03:29 Saephyros a écrit :
Pycharm c'est bloated as fuck en vrai, vaut mieux comprendre comment gérer toi même les environnements, les dependencies et le débugage pour comprendre ce que tu fais
Après je pars de presque 0, j'ai un peu les notions mathématiques mais niveau code en IA c'est 0
J'ai essayé jupyter c'est nul j'aime pas du tout les sortes de cellules

Le 27 avril 2022 à 21:06:25 :
Le 27 avril 2022 à 21:03:29 Saephyros a écrit :
Pycharm c'est bloated as fuck en vrai, vaut mieux comprendre comment gérer toi même les environnements, les dependencies et le débugage pour comprendre ce que tu faisAprès je pars de presque 0, j'ai un peu les notions mathématiques mais niveau code en IA c'est 0
J'ai essayé jupyter c'est nul j'aime pas du tout les sortes de cellules
jupyter notebook = caca
Le 27 avril 2022 à 21:05:37 Saephyros a écrit :
Le 27 avril 2022 à 21:04:29 :
Apparemment le dropout c'est pas vraiment ça
Je demandais plus un truc comme ça
Ya un intérêt?Perso je suis ingé de recherche en deep mais pas claire ton schéma

bah à la couche 1 tu as 4 neurones avec 5 connexions pour 4 neurones à la couche 2 (au lieu de 16 connexions)
intérêt?
Le 27 avril 2022 à 21:08:03 :
Le 27 avril 2022 à 21:05:37 Saephyros a écrit :
Le 27 avril 2022 à 21:04:29 :
Apparemment le dropout c'est pas vraiment ça
Je demandais plus un truc comme ça
Ya un intérêt?Perso je suis ingé de recherche en deep mais pas claire ton schéma
bah à la couche 1 tu as 4 neurones avec 5 connexions pour 4 neurones à la couche 2 (au lieu de 16 connexions)
intérêt?
Dans la vraie vie, go essayer, souvent on est pas sur de pourquoi quelque chose marche 
Le 27 avril 2022 à 21:05:41 Citranus a écrit :
Le 27 avril 2022 à 20:57:02 :
- ça existe déjà : dropout ça permet de renforcer la capacité d'apprentissage du réseau- autre façon de renforcer le message
- ça dépend de ce que tu veux faire, y a pas de "meilleur"
- Pytorch est plus utilisé en ce moment. Mais à ton niveau c'est pas important. Keras ça peut être un bon début
- C'est faisable, ça réduit le nombre de poids pour une même profondeur, donc ça réduit le temps d'entrainement. Le dropout, ce n'est pas ça.
-Ca s'appelle des couches parallèles, 'inception' je crois
-Il faut essayer pour savoir.
-Tensorflow/Keras et Pytorch ont les mêmes performances, c'est surtout la manière d'écrire le code qui change, effectivement keras est le plus simple.
Je m'en fiche que ça soit dur niveau code tant que c'est LOGIQUE
Le 27 avril 2022 à 21:09:24 Saephyros a écrit :
Le 27 avril 2022 à 21:08:03 :
Le 27 avril 2022 à 21:05:37 Saephyros a écrit :
Le 27 avril 2022 à 21:04:29 :
Apparemment le dropout c'est pas vraiment ça
Je demandais plus un truc comme ça
Ya un intérêt?Perso je suis ingé de recherche en deep mais pas claire ton schéma
bah à la couche 1 tu as 4 neurones avec 5 connexions pour 4 neurones à la couche 2 (au lieu de 16 connexions)
intérêt?Dans la vraie vie, go essayer, souvent on est pas sur de pourquoi quelque chose marche

Ayaaaaaaaaaaaa ça se voit que t'es ingé
"ça marche c'est tout ce qui compte"
Le 27 avril 2022 à 21:09:59 :
Le 27 avril 2022 à 21:05:41 Citranus a écrit :
Le 27 avril 2022 à 20:57:02 :
- ça existe déjà : dropout ça permet de renforcer la capacité d'apprentissage du réseau- autre façon de renforcer le message
- ça dépend de ce que tu veux faire, y a pas de "meilleur"
- Pytorch est plus utilisé en ce moment. Mais à ton niveau c'est pas important. Keras ça peut être un bon début
- C'est faisable, ça réduit le nombre de poids pour une même profondeur, donc ça réduit le temps d'entrainement. Le dropout, ce n'est pas ça.
-Ca s'appelle des couches parallèles, 'inception' je crois
-Il faut essayer pour savoir.
-Tensorflow/Keras et Pytorch ont les mêmes performances, c'est surtout la manière d'écrire le code qui change, effectivement keras est le plus simple.Je m'en fiche que ça soit dur niveau code tant que c'est LOGIQUE
en vrai de vrai pytorch est le plus pratique 
Le 27 avril 2022 à 21:08:03 :
Le 27 avril 2022 à 21:05:37 Saephyros a écrit :
Le 27 avril 2022 à 21:04:29 :
Apparemment le dropout c'est pas vraiment ça
Je demandais plus un truc comme ça
Ya un intérêt?Perso je suis ingé de recherche en deep mais pas claire ton schéma
bah à la couche 1 tu as 4 neurones avec 5 connexions pour 4 neurones à la couche 2 (au lieu de 16 connexions)
intérêt?
L'intérêt c'est que pour arriver au résultat de ta couche de sortie, tu as peut être besoin de données qui ont déjà été calculées avant, si tu met un neurone là, il va juste reproduire une donnée, mais tu dépenseras du calcul pour ça, dis toi que chaque trait à l'entrée d'un neurone représente un gradient à calculer pour chaque batch d'entrée à chaque époque, moins il y en a plus ton réseau apprendra vite.
Données du topic
- Auteur
- HunterChasseur
- Date de création
- 27 avril 2022 à 20:54:28
- Nb. messages archivés
- 257
- Nb. messages JVC
- 245