Après avoir scanné Internet (IPv4:80), je m'apprête à enregistrer toutes les pages web
SuppriméLe 11 juillet 2022 à 17:50:23 :
Le 11 juillet 2022 à 17:49:08 :
150 1000go c'est peuIl n'y a pas les CSS avec
Mon site c'est un bête <canvas> avec un script JS qui tourne dedans, du coup t'aura pas grand chose à garder si tu sauvegardes pas le CSS et le JS 
ton estimation de 1000go me semble fausse + this
Le 11 juillet 2022 à 17:51:32 :
Le fameux script python mono thread qui va scan l'ensemble des servers webs

Le 11 juillet 2022 à 17:55:46 :
Peux nous expliquer l'architecture de ton script qui permettra de scan l'ensemble des servers web exposant leur port 80? Comment vas-tu gérer les process, comment gères-tu les threads dans tes scripts?
Quelle méthode déploiement pour paralléliser l'exécution sur plusieurs serveurs?
concurrent.futures
C'est simple, j'ai divisé le fichier en 600 parties, le script les lit un par un puis quand il termine, il supprime le txt temporaire et compresse en .tar.gz
Le 11 juillet 2022 à 17:42:42 :
Ok mon autre fion
J'ai eu du mal à comprendre
Le 11 juillet 2022 à 17:56:49 :
Le 11 juillet 2022 à 17:55:46 :
Peux nous expliquer l'architecture de ton script qui permettra de scan l'ensemble des servers web exposant leur port 80? Comment vas-tu gérer les process, comment gères-tu les threads dans tes scripts?Quelle méthode déploiement pour paralléliser l'exécution sur plusieurs serveurs?
concurrent.futures
C'est simple, j'ai divisé le fichier en 600 parties, le script les lit un par un puis quand il termine, il supprime le txt temporaire et compresse en .tar.gz
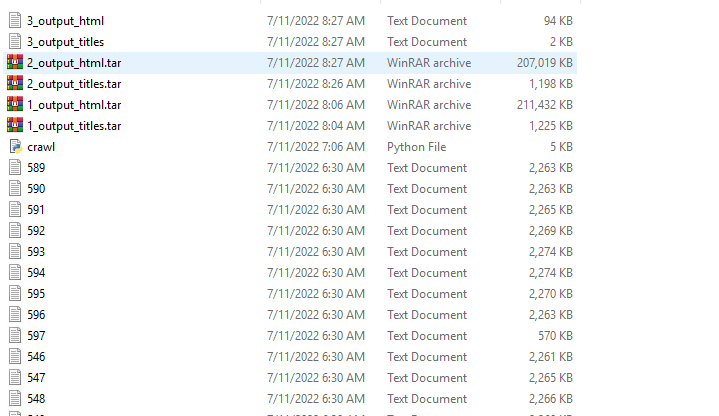
je l'ai nommé crawl mais ce n'est pas le terme exact vu que je me base sur le scan que j'avais fait (59 millions d'IP avec un port 80 ouvert), le fichier contiendra 59 millions de lignes (lorsque la requête a échouée, ce sera marqué failed)
Le 11 juillet 2022 à 17:58:33 :
Le 11 juillet 2022 à 17:56:49 :
Le 11 juillet 2022 à 17:55:46 :
Peux nous expliquer l'architecture de ton script qui permettra de scan l'ensemble des servers web exposant leur port 80? Comment vas-tu gérer les process, comment gères-tu les threads dans tes scripts?Quelle méthode déploiement pour paralléliser l'exécution sur plusieurs serveurs?
concurrent.futures
C'est simple, j'ai divisé le fichier en 600 parties, le script les lit un par un puis quand il termine, il supprime le txt temporaire et compresse en .tar.gz
Mais ça sert à quoi ?
Le 11 juillet 2022 à 17:59:01 :
Le 11 juillet 2022 à 17:58:33 :
Le 11 juillet 2022 à 17:56:49 :
Le 11 juillet 2022 à 17:55:46 :
Peux nous expliquer l'architecture de ton script qui permettra de scan l'ensemble des servers web exposant leur port 80? Comment vas-tu gérer les process, comment gères-tu les threads dans tes scripts?Quelle méthode déploiement pour paralléliser l'exécution sur plusieurs serveurs?
concurrent.futures
C'est simple, j'ai divisé le fichier en 600 parties, le script les lit un par un puis quand il termine, il supprime le txt temporaire et compresse en .tar.gz
Mais ça sert à quoi ?
antoineforum ? à rien pourquoi ?
merci de continuer à faire vivre ce sujet d'antologie

Le 11 juillet 2022 à 17:56:49 :
Le 11 juillet 2022 à 17:55:46 :
Peux nous expliquer l'architecture de ton script qui permettra de scan l'ensemble des servers web exposant leur port 80? Comment vas-tu gérer les process, comment gères-tu les threads dans tes scripts?Quelle méthode déploiement pour paralléliser l'exécution sur plusieurs serveurs?
concurrent.futures
C'est simple, j'ai divisé le fichier en 600 parties, le script les lit un par un puis quand il termine, il supprime le txt temporaire et compresse en .tar.gz
C'est un peu simpliste comme explication 
Combien de thread en parallèle comptes-tu utiliser? Comment vas-tu gérer les impacts CPU? La load?
Quel est ce fichier d'entrée dont tu parles?
Pourquoi 600?
Le 11 juillet 2022 à 18:00:13 :
+ avec toutes les pages web qui sont des SPA ça a peu de sens de juste collecter le html
Le but est de récupérer le contenu HTML des résultats du scan
Le 11 juillet 2022 à 18:01:13 :
Est-ce que tu as mis une limite sur la taille maximale du HTML que tu peux enregistrer ?
Oui, pareil pour le titre et headers, mais c'est une limite très généreuse, c'est vraiment pour éviter les abus
Pour l'encodage c'est UTF-8
Le 11 juillet 2022 à 18:01:52 :
Le 11 juillet 2022 à 18:01:13 :
Est-ce que tu as mis une limite sur la taille maximale du HTML que tu peux enregistrer ?Oui, pareil pour le titre et headers, mais c'est une limite très généreuse, c'est vraiment pour éviter les abus, il y a aussi un timeout
Pour l'encodage c'est UTF-8
Dommage...
Le 11 juillet 2022 à 18:01:33 :
Le 11 juillet 2022 à 18:00:13 :
+ avec toutes les pages web qui sont des SPA ça a peu de sens de juste collecter le htmlLe but est de récupérer le contenu HTML des résultats du scan
ok mais tu vas faire tourner le javascript ? si tu gardes juste le html initial d'une page React, t'auras juste
<div class="root">
</div>
Données du topic
- Auteur
- AntoineForum144
- Date de création
- 11 juillet 2022 à 17:42:00
- Date de suppression
- 11 juillet 2022 à 18:36:15
- Supprimé par
- Modération ou administration
- Nb. messages archivés
- 73
- Nb. messages JVC
- 75